第8天的作業裡word_cnts的那串數字是怎麼來的?
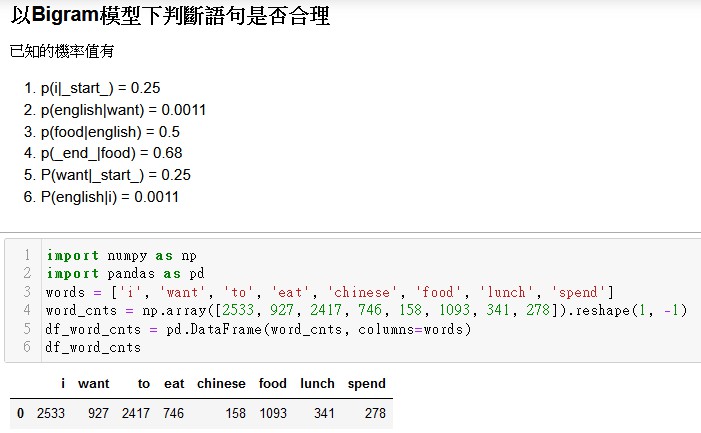 那些單字是怎麼從上面給的機率變成下面那些數字的!?????
回答列表
-
2021/03/03 上午 11:22Poem贊同數:0不贊同數:0留言數:0
學員您好, 此語料庫是來自於 Berkley Restaurant Project corpus。是一段錄音的資料來源。 採用unigram model 計算的數值。 上方的機率值是應用 Bigram計算的,可用在最後一個題目計算的參考。 附上幾篇參考文獻。 [1] http://www.cs.cornell.edu/courses/cs474/2005fa/Handouts/n-grams+smoothing.pdf [2] https://web.stanford.edu/~jurafsky/slp3/ed3book.pdf [3] https://www.cs.toronto.edu/~frank/csc401/lectures/2_Corpora_and_Smoothing.pdf
-
2021/03/03 下午 03:20張維元 (WeiYuan)贊同數:1不贊同數:0留言數:0
嗨,你好
下面這組數字應該是出題者參考某個資料引用而來,在這邊可以視為是「假設每個字分別出現的次數」就好,具體從哪裡來我覺得目前不重要。
嗨,你好,我是維元,持續在不同的平台發表對 #資料科學、 #網頁開發 或 #軟體職涯 相關的文章。如果對於內文有疑問都歡迎與我們進一步的交流,都可以追蹤我的 Facebook 或 技術部落格 ,也會不定時的舉辦分享活動,一起來玩玩吧 ヽ(●´∀`●)ノ 以下分享一些我近期發表跟資料科學有關的文章,歡迎大家持續追蹤: ■ 資料分析工具那麼多,該怎麼選? 🛠️
■ 真.資料團隊與分工
■ 觀察資料的 N 件事 🔖
■ 資料前處理必須要做的事 - 資料清理與型態調整