訓練出來的結果是否算過擬合,又該如何解決呢?
各位好: 想請問近期執行一個數值型回歸預測專案 目前有將資料集分成訓練、驗證集,並以測試集來進行預測 (總資料筆數約3000多筆,特徵數共60個,經由特徵篩選(特徵重要性、相關係數)篩到剩8個,另訓練集有進行標準化前處理,測試集亦有同步進行) 預測效果如下: linear訓練(上)及驗證(下)的結果如下:  linear測試結果如下: 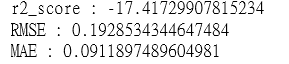 Random Foresr訓練(上)及驗證(下)的結果如下:  Random Foresr測試結果如下:  所以會得到這樣的結果,在測試集預測上均不理想, 會這樣是因為過擬合,模型過於複雜的因素造成的嗎? 但是linear在測試上效果更差,且R2竟然出現負的情形, 也是因為過擬合的因素造成的嗎? 對於這樣的結果有更好的解決方法改善測試集的預測結果嗎?
回答列表
-
2021/07/15 下午 11:02Ray贊同數:1不贊同數:0留言數:2
您好,首先,linear的部分不是過擬合,而是欠擬合,過擬合所代表的意思是模型良好的擬合 訓練數據,但是在面對未知的數據時無法做出正確判斷,通常發生原因是因為模型過於複雜;而欠擬合則是無法良好的擬合數據,也就是訓練不好,而您的情況從訓練結果就能看出未能進行有效的訓練,基本上0.5幾乎等於沒有訓練直接用猜的一樣,因此建議您重新建一個模型來訓練會比較好,同時建議您增加模型的複雜度;而至於第二個部分,就訓練結果和測試結果來看的確是過擬合,能請問您這如何去劃分訓練、驗證、測試集的數量嗎,您的模型就訓練結果來看並不差,有很好的訓練到,具體問題有可能是您的資料特徵分佈不均導致,比方說在訓練集的部分A、B、C特徵分佈較多,而D較少,但在測試集則剛好相反,這也會導致您的訓練和測試結果出現較大的落差,另外就是您的資料樣本數偏少,建議您只分成訓練集和測試集就好,不必在另外多劃分驗證集,因為驗證集並不是必須的,通常是在資料樣本數充足的情況下為了取得更好的結果才劃分的,希望這能幫助到您~
-
2021/07/21 下午 07:47Yilin贊同數:0不贊同數:0留言數:5
linear的訓練結果由R2 score看到負值。即代表模型訓練出來無預測能力(跟隨便亂猜的一樣),即表示欠擬和。這要看你的資料是否有時間序列的因素?有可能訓練跟測試是切不同的時段分佈。如果要處理時間序列的資料可以先觀察每個特徵是否平穩。因為這些資料隨時間變化,它的分佈可能具有獨特的屬性,例如季節性和某種趨勢。相對的這些非平穩的特徵會導致資料的平均數和方差有極大的擾動,從而難以對這些非平穩的資料進行模型訓練。因此使資料的分佈平穩是時間序列預測中的最基本要求。