讀取xmltodict解析後的檔案,出現問題?
我在讀取xmltodict解析後的檔案時,出現問題。 我先用筆記本打開看xml結構,以為可以直接像下面方式找出,但不行。 好像要用迴圈方式找,但怎麼判斷何時用迴圈存取? 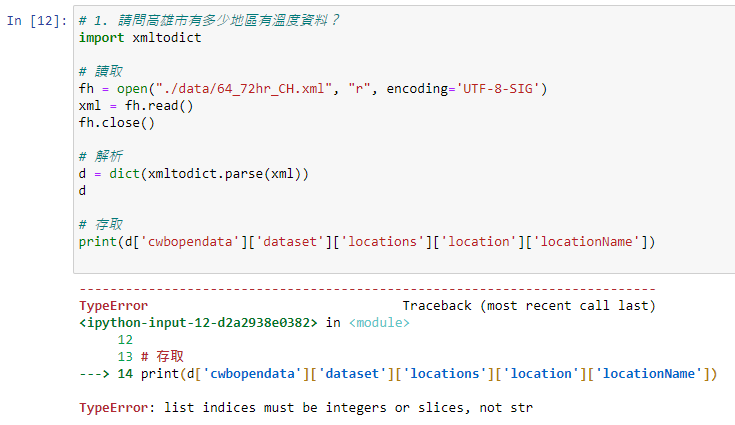
回答列表
-
2022/02/07 下午 03:30Johnny贊同數:1不贊同數:0留言數:1
同學你好: 上述程式碼會產生錯誤的原因在於:使用字串作為 index 來存取 list 物件中的元素 如下方程式碼: ```python import xmltodict with open('64_72hr_CH.xml', 'r') as fh: xml = fh.read() d = xmltodict.parse(xml) print(type(d['cwbopendata']['dataset']['locations']['location'])) # output:
``` 表示 d['cwbopendata']['dataset']['locations']['location'] 已經是一個 list 物件而非 OrderedDict 物件,因此無法透過字串 (locationName) 作為 key 來取得裡面的元素。 --- **何時應該使用迴圈來取得元素?** 最簡單的方式即是根據目前是什麼「物件」,如果是 list 物件,則透過迴圈取得 list 中的每一個元素;如果是 dict 或是 OrderedDict 物件,則是根據你想要的資訊指定相對應的 key。 舉例來說: 我想要取得 d['cwbopendata']['dataset']['locations']['location'] 中「每一個」location 的資訊,就可以透過迴圈: ```python for lcn in d['cwbopendata']['dataset']['locations']['location']: print(lcn) ``` 如果我想要更進一步地針對單一個 location 取得他的名字,因為 lcn 已經是 OrderedDict,因此我們使用 key: ```python for lcn in d['cwbopendata']['dataset']['locations']['location']: print(lcn['locationName']) ```