請問我對於DANN域遷移學習的理解與原理是否正確?
Hi, 請問影片內提及的上課slides跟demo的jupyter notebook,要去哪下載呢? 另外對於本週影片內的範例,麵粉袋,想請問下我的以下五點理解是否正確。 1. 神經網的架構大致上可分為三塊,分別是 Feature Extractor, Label predictor 與Domain classifier。 2. 在輸入的圖片與真正應用時所用的圖片差異不大時,僅需要兩塊(即原本已完成的訓練的模型)就可以完成辨別。 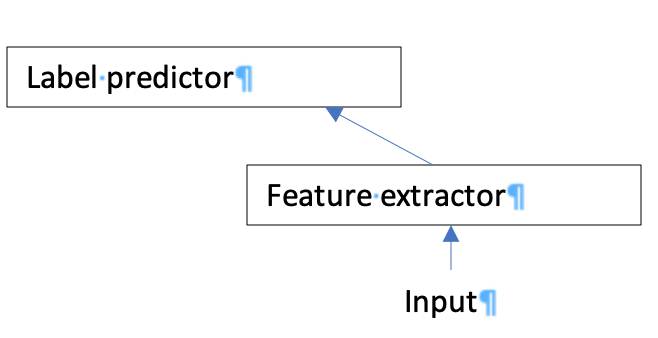 3. 然而如果真正應用時所用的應用圖片與訓練圖片差異大(如光線不同,但基本上都是辨識麵粉袋),就需要增加入一個分支的神經層Domain classifier才能完成辨別。由Domain classifier來負責消除應用圖片與訓練圖片的差異。且Label predictor 及Feature extractor內的神經元權重也會因Domain classifier的存在(loss function)而被修正。 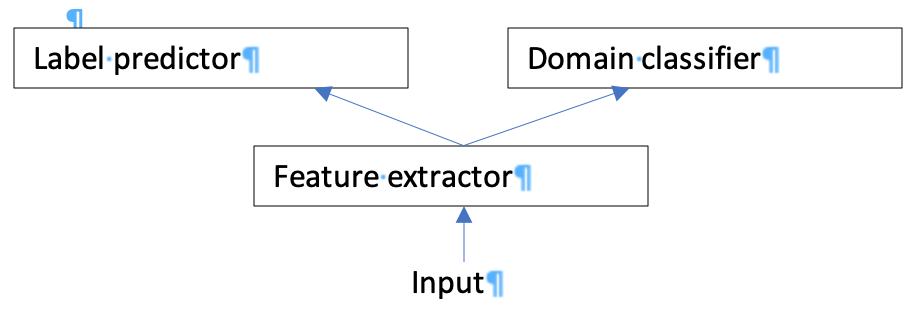 4. 且因為是利用已完成訓練的模型,再做重新訓練,擬合新得sample至一定水平的sample數量需求,會少於重頭訓練一個新模型的數量需求,且時間成本更小。 5. 跳脫範例的話,Domain classifier也可理解為用來消除應用資料與訓練資料的差異(如搜集時產生的bias)的一層神經網。可以將新的sample拿來對已存在的模型參數做重新訓練,最後獲得更泛化的模型。 謝謝。
回答列表
-
2020/12/25 下午 04:45Jimmy Chiang贊同數:4不贊同數:0留言數:1
嗨,您好,我也算是微入門的人,希望我的見解對你有幫助。有錯誤也歡迎指正~ 1. Rex 所說的Feature Extractor, Label predictor, Domain classifier 應該算是眾多類神經網路的一個集合,為了簡化解釋模型的架構~如果是做影像辨識,那很多都是靠名為CNN的類神經網路,可以上 [PyTorch](https://pytorch.org/docs/stable/nn.html) 看到一些真實在跑模型的時候會使用的 layers。 2. 對~但是差異大不大不是我們人眼就能判斷的,還是要經過真實輸入資料這個步驟來驗證你的訓練資料和目標資料是同 domain 3. 對,NN 都會有 feedback,因為加入了Domain classifier 這部分的類神經網路,重新訓練時會導致前面的 Feature extractor 的權重改變,進而改變到 Label predictor 的權重。 4. 可以這麼理解 5. 我認為應該解釋為,目前問題是因環境不同導致模型精准度下降。台灣廠和越南廠唯一的差別也只有光線(可以觀察 Rex 那時秀出的照片,角度大小等等都相同),因此才想到用 Classifier 的方式讓模型無法分出台灣廠和越南廠。情況會因著問題不同而有不同的解法~並不是 Domain classifier 就是拿來消除消除差異而產生的,而是這個狀況,適用於用 Classifier 來混淆模型。 歡迎討論:)
-
2020/12/28 上午 07:26Rex贊同數:1不贊同數:0留言數:0
謝謝Jimmy的詳細回答 我這邊回覆您第四點,時間成本小很多,以我們處理的案件(澱粉袋)來做範例,訓練時間縮短為1/4,對於整個產品來說是非常有幫助的。 第五點,關於domain adaptation我認為是非常重要的課題,例如我們在做AOI(自動光學檢測),明明就有之前搜集過上萬的資料集,卻因為拍攝方式不同而有不同的domain,透過這樣的方式可以節省很多資料成本。