我用pd.pivot_table(score_df, index=['sex','class','student_id']),返回值似乎很相近,不知和df.pivot()的用法差異在哪呢?
以下是我的返回值: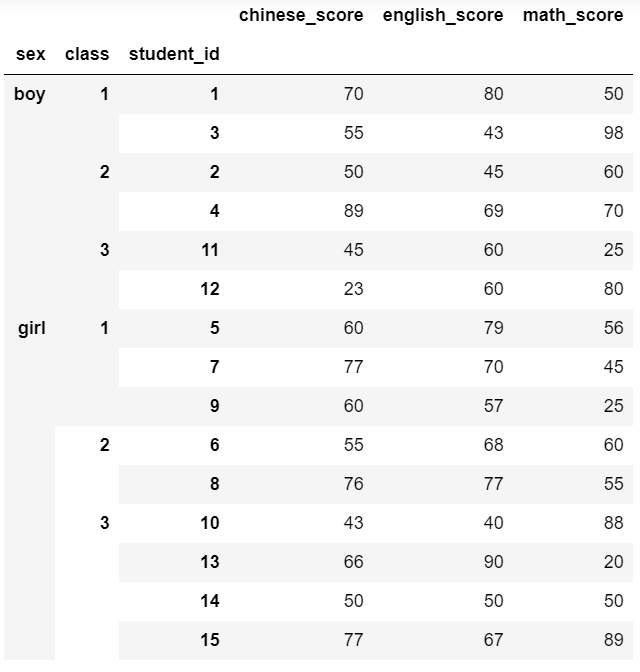
回答列表
-
2021/01/29 下午 09:47李柏霆贊同數:0不贊同數:0留言數:0
pivot 和 pivot table 的差異可以參考這篇文章,寫的很清楚 https://blog.csdn.net/ljr_123/article/details/105164337
-
2021/01/30 上午 02:28張維元 (WeiYuan)贊同數:0不贊同數:0留言數:0
嗨,你好
他們都可以達到樞紐分析的效果,也就是重新排列,差別在於 pivot 比較嚴格一點(要求 index & column 成對),舉個例子: ``` df_test = pd.DataFrame({ 'foo': ['one','one','one','one','two','two'], 'bar': ['A', 'B', 'C', 'A', 'B', 'C'], 'baz': [1, 2, 3, 4, 5, 6] }) ``` 當中 foo 當中的 one 有四個, two 只有兩個 跟 bar 的各三個對不起來。因此,pivot 會跳錯誤,pivot_table 可以跑出結果:  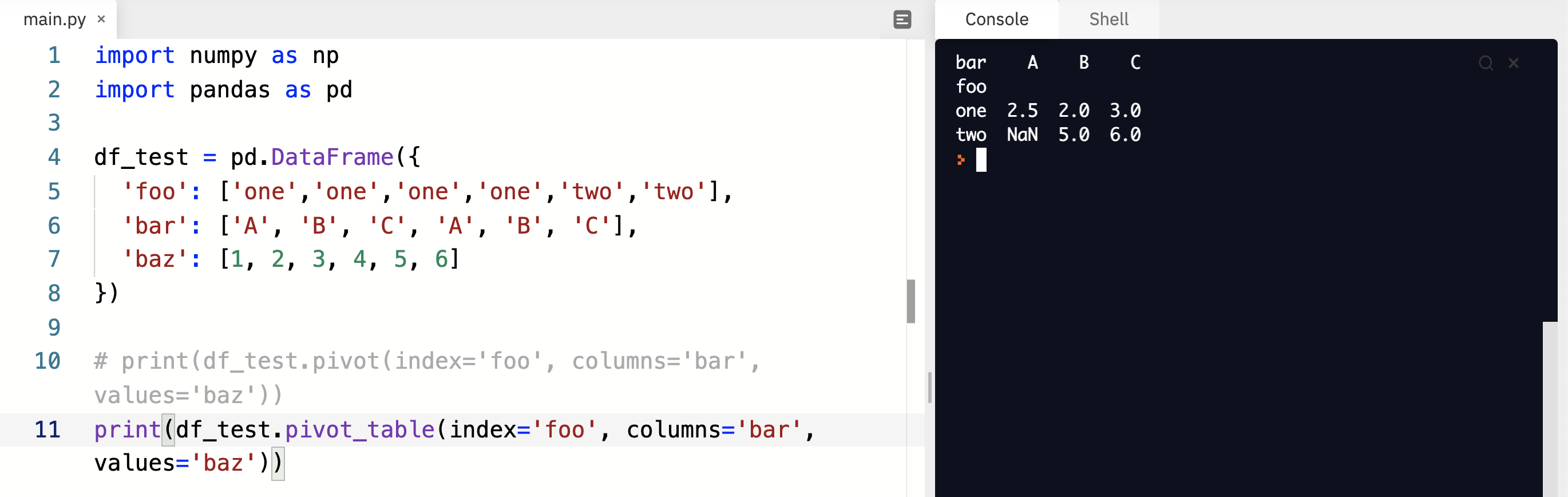
嗨,你好,我是維元,持續在不同的平台發表對 #資料科學、 #網頁開發 或 #軟體職涯 相關的文章。如果對於內文有疑問都歡迎與我們進一步的交流,都可以追蹤我的 Facebook 或 技術部落格 ,也會不定時的舉辦分享活動,一起來玩玩吧 ヽ(●´∀`●)ノ 以下分享一些我近期發表跟資料科學有關的文章,歡迎大家持續追蹤: ■ 資料分析工具那麼多,該怎麼選? 🛠️
■ 真.資料團隊與分工
■ 觀察資料的 N 件事 🔖
■ 資料前處理必須要做的事 - 資料清理與型態調整