selenium 抓取問題 求解抓取後內容失敗
我想要透過selenium抓取下列連結的內容,但是我始終抓不到表格裡面的內容值,請問是我的等待時間過短嗎?
http://fgj.wuhan.gov.cn/bsfw_44/zxsbhcxxt/fdcjjjg/
回答列表
-
2020/08/11 下午 03:08Jia贊同數:1不贊同數:0留言數:2
我從"開發人員工具" > "Network" 搜尋隨便一個字串,發現到它是從另一個網頁過來的,因此GET那個網址([http://119.97.201.22:8083/search/zzzz/zz_zhongjie2.aspx](http://119.97.201.22:8083/search/zzzz/zz_zhongjie2.aspx))就能抓取到表格內容了。 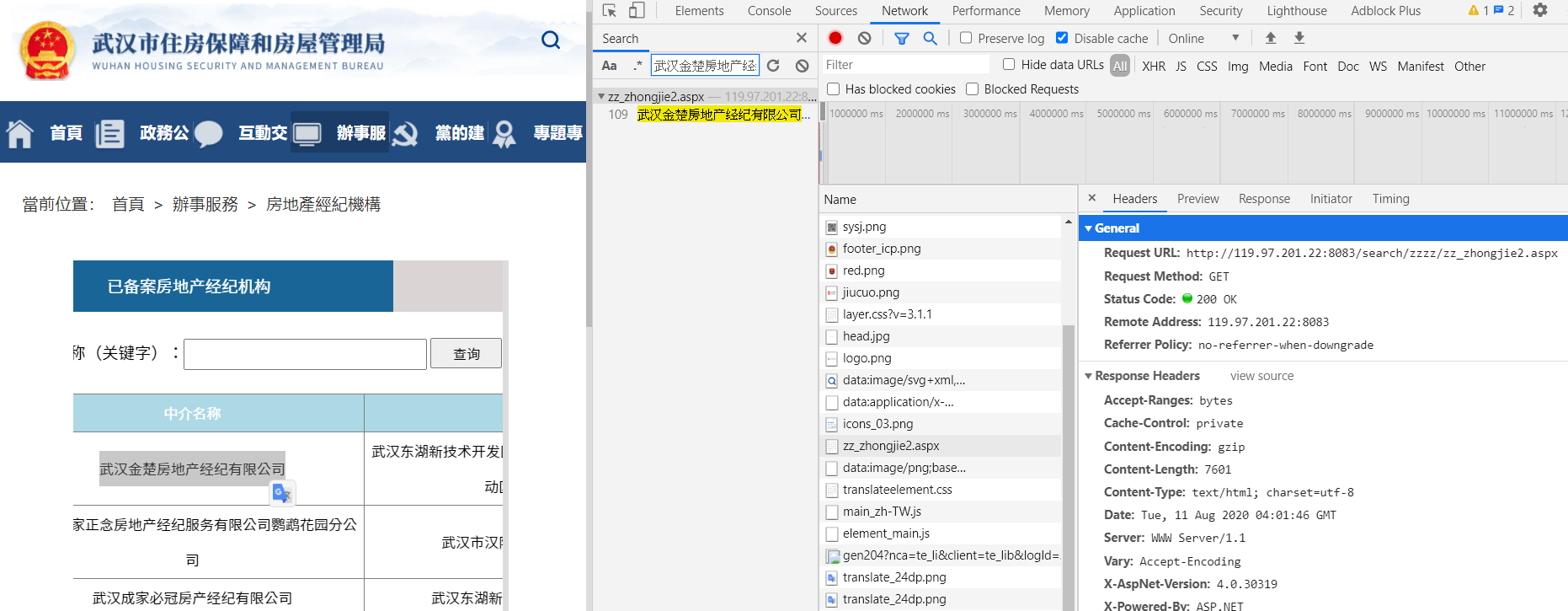
另外從原本網頁的原始碼也可以看到,它是使用 iframe 內嵌框架嵌入另一個網頁。 
那為何 Selenium 會找不到資料? 稍微google搜尋"**selenium iframe**"會知道,想抓取 iframe 內的內容就需要先切進去,才能取得資料。 ```python browser.get("http://fgj.wuhan.gov.cn/bsfw_44/zxsbhcxxt/fdcjjjg/") time.sleep(10) browser.switch_to.frame(0) # <--- html_source = browser.page_source html_source ``` -
2020/08/13 下午 11:37張維元 (WeiYuan)贊同數:0不贊同數:0留言數:0
嗨,這是一個好的例子,會建議像 Jia 先從檢視原始碼的部分先找找看,最後才用程式來爬,不要一開始就用程式。
如果這個回答對你有幫助請主動點選「有幫助」或「最佳解答」的按鈕,也可以追蹤我的GITHUB 帳號。若還有問題的話,也歡迎再開一個新的問題繼續發問,或者把你理解的部分整理上來,我都會提供你 Review 和 Feedback 😃😃😃另外我目前有舉辦一個社群活動:學員限定!CUPOY 馬拉松線上小聚 👨🏻💻👨🏻💻,歡迎一起來玩玩!