【QA】如何理解協同過濾演算法背後的概念 ?
我們在 [甚麼是協同過濾?](https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017D522E7781000000196375706F795F72656C656173655155455354) 提到協同過濾的概念,這篇會介紹基於記憶的(Memory-based)協同過濾演算法,並以 User-based 為例,更深入理解演算法的機制。
回答列表
-
2021/11/24 下午 09:52Tim贊同數:0不贊同數:0留言數:0
## 演算流程 整個演算流程其實就呼應了協同過濾的主要概念。以 NETFLIX 為例,針對某觀看用戶 A,我們首先會找出和 A相似的用戶,並看看這些與 A使用者相似的用戶都看哪些影集,再推薦給 A使用者。但你可能會想問: 1. 要怎麼決定哪些用戶和 A用戶相近? 2. 假設已經找出和 A相近的用戶,如何決定推薦哪些影集(A 用戶對影集的評分)? 協同過濾演算法其實就是透過數學解決以上兩個問題,特別要注意的是,以上的問題並沒有唯一的答案,計算用戶的相似度和計算評分有許多不同的方式,但一般的情況下,用戶之間的相似度會透過用戶對影集的評分來計算而得,也就是如果兩個用戶對影集都有相似的評價,則他們的相似度就會較高。 以下會介紹 1. 甚麼是 USER-ITEM MATRIX? 2. 如何計算用戶間的相似度? 3. 如何透過相似的用戶計算使用者對物品(item)的評分? ## 甚麼是 USER-ITEM MATRIX? 協同過濾演算法的資料來源包含使用者(user)對物品(item)的評價資訊, 這裡所稱的評價資訊可以是評分分數(如1-5分)、瀏覽次數、瀏覽時間等反應使用者喜好的訊息。資料來源通常以矩陣(matrix)的形式呈現,矩陣的每列代表特定使用者對各物品的評分,而每行則代表該物品從不同使用者所得到的評分 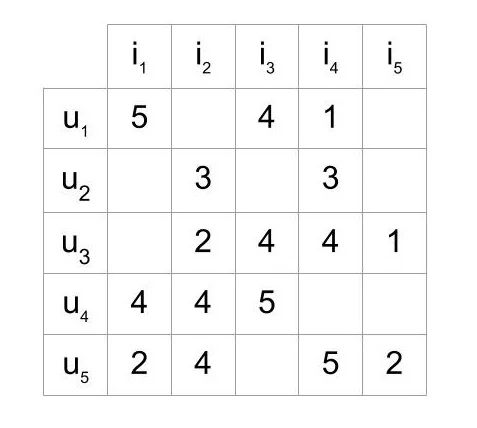 此範例矩陣表示五位使用者對於五個物品的評分,評分介於 1~5 之間。 大多情況下,使用者不會對每個物品都有評分,也有可能矩陣中大多皆為空白(即沒有評分資訊),即該矩陣為稀疏矩陣。 ## 如何計算用戶間的相似度? 用戶對物品的評分(Rating),其實已經反映了用戶的喜好,而每個用戶對不同物品的評分,其實都是一組向量,就可以利用常見計算向量間距離的方法,得到用戶間的相似度。 常見有兩種計算用戶相似度的方式: 1. 皮爾森相關係數 (Pearson correlation coefficient) 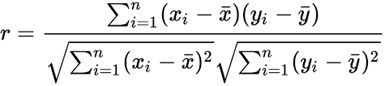 2. 餘弦相似度 (Cosine Similarity) 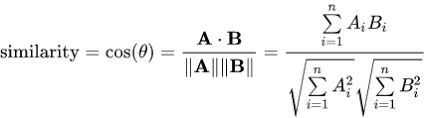 ## 如何透過相似的用戶計算使用者對物品(item)的評分? 得到其他用戶與某使用者 U 的相似度後,接著要計算該使用者 U對特定物品I 的評分 R,和計算相似度一樣,計算評分的方式也不只一種。以下舉例其中兩種常見的方式。 一種方法是,預測使用者 U對物品 I的評分,可以由前 n位與使用者 U最相似的用戶來決定。這前 n位最相似的用戶對物品 I平均評分,就會是預測使用者 U對物品 I的評分。這也相對好理解,如果在 Netflix 上與使用者 U最相似的五個用戶都對某部喜劇平均來說有很高的評價,那我們就會預期使用者 U也會對這部喜劇有很高的評價。 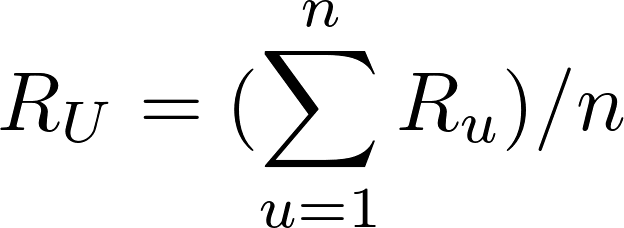 但你發現了嗎?上述的方法在計算評分時並沒有考慮使用者 U和其他用戶的相似性,也就是說,不管這前 n個最相似的用戶與使用者 U的相似度為何,這些用戶對物品 I的評分對於預測都有一樣的權重,舉例來說,可能前五個與使用者 U最相似的用戶中,只有前三個用戶有較高的相似度,後兩個的相似都很低,在這個情況下,我們會期待前三個用戶應該對預測要有更大的影響。 故另一種方法則是在預測評分時,也考慮不同用戶與使用者 U的相似性。對於每個與使用者 U相似的用戶,將該用戶對於物品 I的評分,再乘以該用戶與使用者 U的相似度,故用戶間的相似性在計算上可以視為評分的權重,相似度越高,則該用戶對預測評分的影響就越大,在計算上能更完整且精準的預測評分。 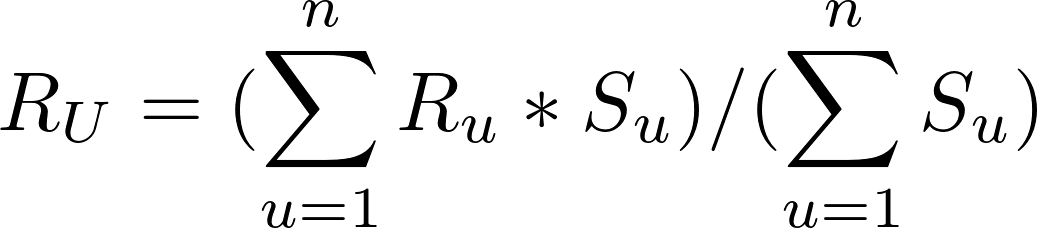 在上述的公式中,RU 代表了使用者 U對物品的預測評分,而 Su 代表用戶 u和 使用者 U的相似度,Ru則代表用戶 u對物品 I的評分。公式中每位用戶對物品 I的評分都乘以該用戶與使用者 U的相似度,故與使用者 U較相似的用戶,對於最終預測的評分影響也較大。 ## 結語 協同過濾演算法涵蓋了許多不同方法,本篇由 user-based (依照使用者之間的相似性推薦物品) 的角度來介紹 Memory-based 協同過濾演算法。而協同過濾也有 model-based 的作法,那就會是另外的主題了。 ---- 參考: 1. https://realpython.com/build-recommendation-engine-collaborative-filtering/ 2. https://towardsdatascience.com/collaborative-filtering-based-recommendation-systems-exemplified-ecbffe1c20b1