【QA】特斯拉放棄雷達和光達系統只用純視覺?
今天要討論到深度學習的一個大領域"Computer Vision"電腦視覺。 然而市值剛進兆元俱樂部的特斯拉,在AI技術方面特別倚賴這項技術...
回答列表
-
2021/11/09 下午 00:29Kevin Luo贊同數:0不贊同數:0留言數:0
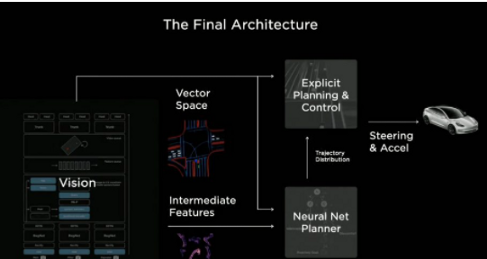
**大部分技術只靠純視覺演算是否靠譜?** 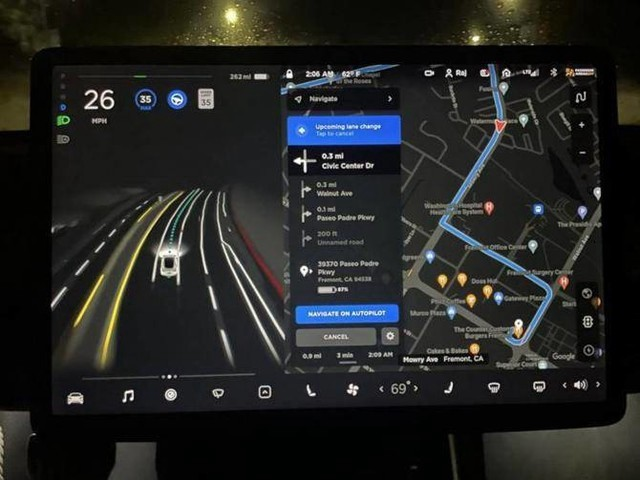  上圖是特斯拉FSD(Full Self Driving) Beta最新的可視化界面(Visualization interface)。這是特斯拉所感知到的世界的樣子。特斯拉就像一個人,但只是他看到的世界與我們有些不一樣。 馬斯克說了一個關鍵詞"mind of car",也就是說車子是有它自己的思維,簡言之…一切的核心都是這個人工智慧到底強不強大。It’s all about AI !直接開門見山的破題AI day. 所有的傳統車企業幾乎都在思考著如何數位轉型或是造全電動車的時候,特斯拉已經在思考的是如何賦予車「思維」。換個角度想…所以特斯拉是在造車嗎?我怎麼覺得還不如說特斯拉在造的是個有車子外型、有車子功能的智慧機器人。 特斯拉這個企業呀,我也完完全全不打算把它歸於一家"車"的公司,我把它歸於一家AI和能源永續公司。這也就是為什麼老馬在演講中常常說: 特斯拉絕對不僅僅是一家車企業。 馬斯克認為在未來電腦會厭倦與人類溝通,因為與其(電腦)相比之下,我們的思考還要比電腦慢得太多。人類講話的訊息量單位大概只有幾百幾千,但電腦可以輕易達到兆的級別(甚至更高好幾個order)。當AI得到極大的發展,電腦只會不耐煩與人溝通,想像一下你和一顆石頭講話是什麼樣子大概就是未來的電腦對我們人類講話的感覺。 所以馬斯克也創立了Neural link 公司,來做腦部移植電腦運算這件事… 只能說…Elon Musk腦中構想的AI和我們平常接觸的AI是完全不同維度上的東西呢(苦笑)。 那進入一下重點: 為什麼馬斯克要不在所有特斯拉上面裝雷達和光達呢? 或許有很多人覺得馬斯克這點盤算錯誤,在讓車子做到精準預測這件事怎麼能不裝這兩樣device? 所以真的覺得馬斯克不懂雷達或光達嗎? 答案肯定是否定的…馬斯克很清楚是什麼(在前面的補充也提到其實他們在某些蒐集資料的車上是有裝雷達的,來輔助視覺,一旦這些資料被蒐集起來就能過渡到其他沒有裝雷達的車上,而且"效果會是一樣強大的"。),而且更清楚它們"極高的成本"。但Elon musk並不只是為了省成本才不裝雷達和光達,因為他自己曾經說過: "全世界的道路,都是為了人類駕駛而設計的。" 這句話算是特斯拉的奧義,背後的邏輯是:道路是為了人類駕駛而設計的,如果擁有和人類駕駛一樣的感知,和處理訊息的能力那就可以無縫過渡到FSD上。這也是最為經濟和高效的方案。 視覺是訊息密度以及訊息量最大的駕駛感知途徑。 燈光、顏色、圖案、物質的材質、高低深遠等眾多的訊息都包含在視覺感知裡面。而且視覺還包含著物體的位置、距離、速度和加速度等物理訊息。 在大部分人的認知中距離的判定大概就只靠雷達來偵測,這是錯誤的,其實視覺也包含著這部份訊息。 想像一下,我們在開車的時候,是不是可以透過雙眼的視覺來大概判定物體的距離和速度?雖然無法精確的判斷出數據。 純視覺雖然無法做到像有雷達一樣精準,但用來開車是絕對夠用的。反觀雷達,它只能判斷到物體,但它不知道物體是什麼。 這時後就要問大家一個問題… 你願意讓一個視力正常的老司機送你回家,還是一個視力2.0但才剛考到駕照的新手司機送你回家? 我相信大部分人都會選擇給老司機載吧? 老司機精通各種回家的大路小路,視力很好的新手司機可能還會迷路… 這樣你懂差別在哪了吧? 現在市面上標榜自己有level 2 auto pilot駕駛的傳統油或油電車都是裝雷達來判斷物體進行的輔助駕駛。事實上這些雷達裝置可能連一個菜鳥駕駛都不如。菜鳥還可以muti-task ,雷達就是只能判斷物件,而且還可能被電磁波干擾。 事實上再好的雷達或光達若是不搭配視覺感官計算,都只能實現輔助駕駛。不可能做到自動駕駛。 那通過以上的描述大家應該也了解視覺在FSD上有多重要。 特斯拉現在在車子上做的就是"模擬人類的一整套視覺和大腦系統"。 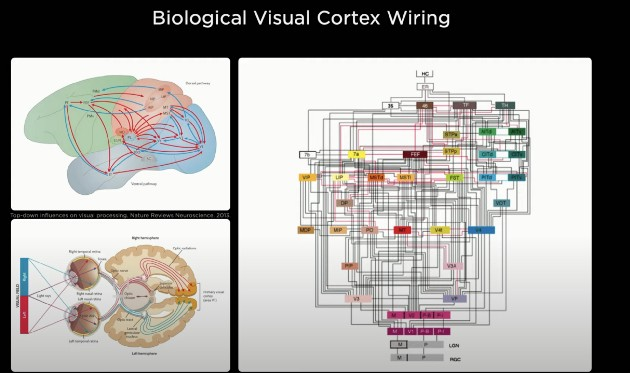 **如何做到模擬人類視覺並且精準預測?** 在特斯拉周圍裝上八顆環繞攝像機:   這些攝像頭的原理和人類接收視覺的原理很像,都是透過採集光訊號的一些light-based sensors. 特斯拉導入AI演算法的第一步就是對所有這些攝像機拍到的影像進行預處理(Data Preprocessing)。這項可以說是在AI pipeline上最最繁雜的一項。 那在影像預處理當中的第一步就是對這些圖像進行校準(Scaling). 為什麼要進行每個圖像校準呢? 因為在所有車上的所有攝像頭不可能都安裝的一模一樣,位置、角度可能都會有些微的不同。然而特斯拉又是靠純視覺的FSD所以圖像一開始的一致性至關重要。 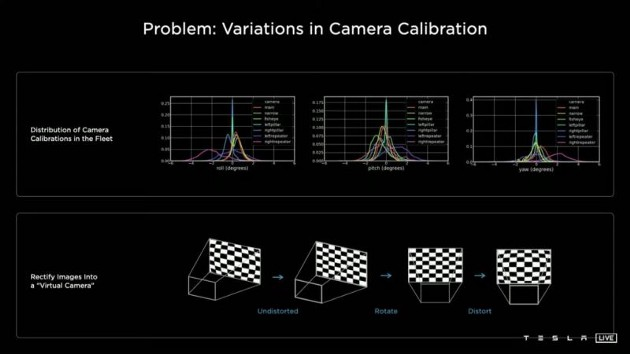 再來就是他們的AI框架和算法: 擁有八個攝像頭,背後是被稱為HydraNets — — “九頭蛇網絡”的多任務學習神經網絡(Based on Transformer:https://zh-yue.wikipedia.org/wiki/Transformer_(%E6%A9%9F%E6%A2%B0%E5%AD%B8%E7%BF%92%E6%A8%A1%E5%9E%8B))。 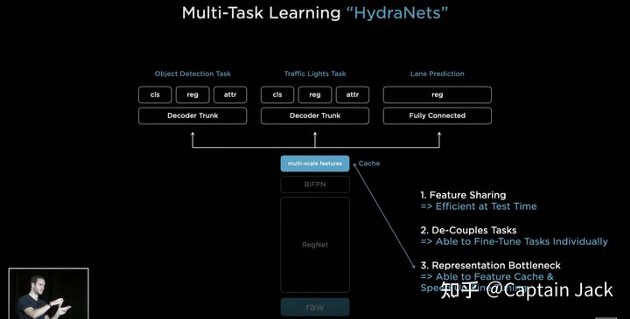 “九頭蛇網絡”可以同時處理目標檢測、交通標志識別、車道預測等等任務,其關鍵在於對各種數據的特徵提取(feature extraction),包括不同種類數據的特徵共享、對不同任務的分別調參(fine-tune),以及參數暫存,用來加快調參速度。 這也是實現FSD敏捷開發,半年內迭代2–3個版本的關鍵。 接下來, Andrej Karpathy 描述了純視覺方案的歷史,以及方案發展到今天的邏輯,他展示了一段特斯拉處理其圖像數據的影片。  Andrej Karpathy說,過去 的FSD 雖然很好,但事實證明這樣的系統不夠完善,每個攝像頭能夠檢測到工程師預期的目標,但背後神經網絡的張量空間是遠不夠的。 於是,特斯拉如重新設計了神經網絡,就是上面的“九頭蛇”架構。  特斯拉方面還比較了多攝像頭方案和單攝像頭方案的差別,相同的場景下,單顆攝像頭方案識別率明顯低於多攝像頭方案。  特斯拉車輛上的8個攝像頭獲取原始輸入後,系統會創建各種分辨率的圖像,用於各種功能和目的。 這些不同的圖像會被分別input給處理不同任務的神經網絡,作為整個自動駕駛系統的決策依據。 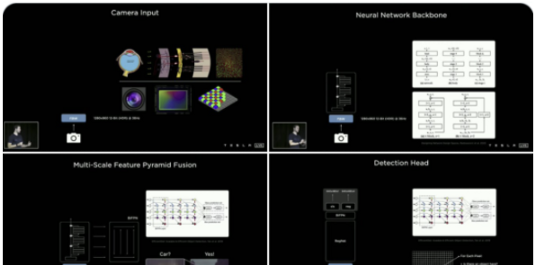 接著,Andrej Karpathy介紹了特斯拉的“終極建築師”,即車輛在行駛過程中可以real-time的對車道、環境進行建模。(能real-time非常厲害! 車道線real-time建模,其實換句話說,就是特斯拉自己的高精地圖能力。 某中國大廠華X的自動駕駛電動車,特別強調“高精度地圖”和雷達、光達。但特斯拉的思路是“現成資源”不是本質能力,本質能力應該是“創造資源”的能力。這讓我想起我最近看的一本書"無限賽局"(其定義可參考連結),特斯拉的思維一直是以"無限的思維"方式在市場中,還其它車廠總是以"有限思維"的方式在進行商業對策。 最後,Andrej Karpathy談了AI公司常見的數據標籤(Data labeling)問題,他認為,把數據外包給第三方去做手工標記並不好,所以特斯拉選擇自建團隊來給數據標籤,目前已經從2D圖像標記升級到4維張量空間的標記。 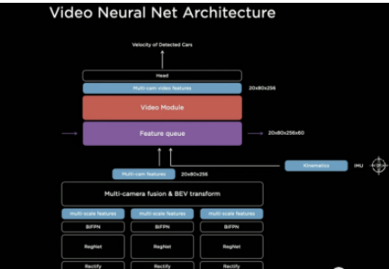 這也是特斯拉自動駕駛不斷快速進化的核心所在。 依靠人工標記,顯然無法應對量產車上路後的大規模數據,所以產生自動化標記,才能形成數據閉環,快速的使"Data Driven"。 AI day上,特斯拉也展示了如何從車道線、2D圖像……一點點躍遷至4D標註和建模的。 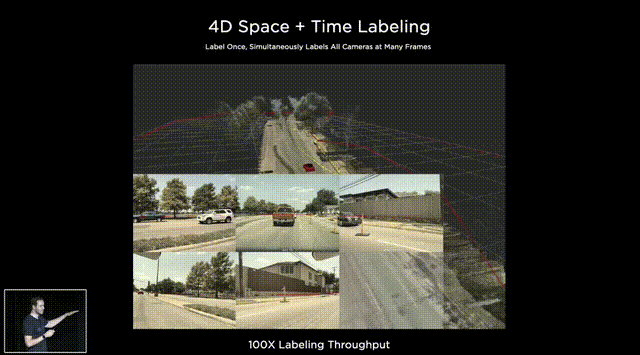 行人、車輛、樹木,建築物……清清楚楚,而且還有意圖識別。  特斯拉方面也強調,基於類腦一樣的感知系統、自動化標籤能力,以及仿真,確保了特斯拉為什麼可以基於純視覺實現更高維度的自動駕駛。 仿真,簡單講就是利用現實數據,將真實世界的實時動態景象,在電腦系統實現重新構建和重現。 這套模擬程序,用特斯拉的話說,就是一個以自動駕駛為玩家的Video Game。 在這套系統裡,任何要素都可以被添加其中,包括非常極端的場景。 也是為了大大提高特斯拉的Generalization,"我看得比人類多的太多太多太多"在這個Simulation當中! 比如這裡,人太多導致目標難以標記,車輛極多:  特斯拉這裡還不忘調侃一下雷達: 純視覺也能做很好,所謂的雷達作用相當有限。 特斯拉表示,現在標註和仿真系統,可以模擬數量高達3.71億的數據及場景。而這些模擬主要是在強化學習(reinforcement learning)下進行的。 當然,自動駕駛最後還得解決從虛擬世界走向真實世界應用的問題。(總不能一直在模擬的強化學習世界裡)。 這次AI day特斯拉主要披露了控制和規劃方面的進展。 特斯拉自動駕駛總監Ashok Elluswamy,分享了特斯拉針對復雜場景的規劃方案 :“混合規劃系統”。 主要思路和技術方法是基於蒙地卡羅搜尋樹來實現所謂最佳路徑規劃。 最後,整個特斯拉自動駕駛從感知到決策規劃,一圖概括如下: