【QA】循序向後選擇演算法(Sequential Backward Selection)?
本次想要與各位一同了解一下循序向後選擇演算法(Sequential Backward Selection),也可以簡稱為SBS演算法
回答列表
-
2021/10/01 下午 09:00Ray贊同數:0不贊同數:0留言數:0
循序向後演算法是一種特徵選擇演算法,經由特徵選擇(feature selection)來對資料進行降維(dimensionality reduction),以達到減少模型複雜度、提高模型泛化程度避免overfitting的效果,以下為特徵選擇演算法的分類: 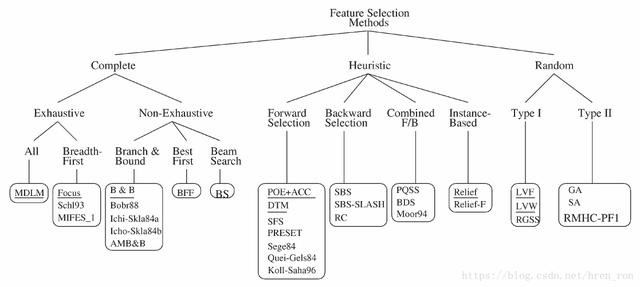[參考圖片來源](https://kknews.cc/code/v3jlv54.html) 本次所要介紹的循序向後演算法便是其中一種,循序向後演算法屬於貪婪演算法(greedy algorithm)中,搜尋演算法的一種。他能夠對A維度的特徵空間進行降維至B維,其目的是選擇與要解決的問題最為相關的的特徵子集合,並移除不相關的特徵(或稱為雜訊、噪音),以提高計算效率或降低模型的一般化誤差,對於未經正規化的模型來說更是效果拔群,在overfitting的情況下,甚至能夠提升模型的預測能力。 SBS演算法的概念十分簡單,SBS演算法會從特徵空間中移除特徵,直到特徵空間中只剩下包含重要資訊的特徵,為了確定哪些特徵需要被移除,SBS演算法定義了一個『準則函數(criterion function)』,由準則函數計算出的準則可被定義為模型在移除特定特徵之後與之前的預測效能的差異,也就是說要移除一些對於預測效能沒有幫助、甚至是造成預測效能下降的特徵 ----------- 基本上SBS演算法的運作過程可大致被分為四個部分: 1. 以k=d初始化演算法,其中d代表特徵空間的維度 2. 找出能最大化準則的特徵 3. 將該特徵從特徵空間中移除 4. 重複2、3步驟直到k等於所需特徵數時停止 ----------------- 以下為SBS演算法的python程式碼: ```python from sklearn.base import clone from itertools import combinations import numpy as np from sklearn.cross_validation import train_test_split from sklearn.metrics import accuracy_score class SBS(): def __init__(self, estimator, k_features, scoring=accuracy_score, test_size=0.25, random_state=1): self.scoring = scoring self.estimator = clone(estimator) self.k_features = k_features self.test_size = test_size self.random_state = random_state def fit(self, X, y): X_train, X_test, y_train, y_test = \ train_test_split(X, y, test_size=self.test_size, random_state=self.random_state) dim = X_train.shape[1] self.indices_ = tuple(range(dim)) self.subsets_ = [self.indices_] score = self._calc_score(X_train, y_train, X_test, y_test, self.indices_) self.scores_ = [score] while dim > self.k_features: scores = [] subsets = [] for p in combinations(self.indices_, r=dim - 1): score = self._calc_score(X_train, y_train, X_test, y_test, p) scores.append(score) subsets.append(p) best = np.argmax(scores) self.indices_ = subsets[best] self.subsets_.append(self.indices_) dim -= 1 self.scores_.append(scores[best]) self.k_score_ = self.scores_[-1] return self def transform(self, X): return X[:, self.indices_] def _calc_score(self, X_train, y_train, X_test, y_test, indices): self.estimator.fit(X_train[:, indices], y_train) y_pred = self.estimator.predict(X_test[:, indices]) score = self.scoring(y_test, y_pred) return score ``` ------------- 有興趣進一步了解的人可參考以下連結: * [【来点干货】机器学习中常用的特征选择方法及非常详细的Python实例](https://zhuanlan.zhihu.com/p/141010878) * [机器学习-特征选择-序列后向选择Sequential Backward Selection方法](https://blog.csdn.net/Santorinisu/article/details/104418096) * [機器學習算法:特徵選擇神器FeatureSelector](https://kknews.cc/code/v3jlv54.html) * [總結 特徵選擇(feature selection)演算法筆記](https://www.itread01.com/content/1546133794.html)
-
2022/05/29 下午 08:53王健安贊同數:0不贊同數:0留言數:0
## 為何要挑選有用的特徵? - 不是所有特徵對目標的預測都有幫助 - 沒有影響力的特徵容易對預測目標造成負面影響 - 特徵之間的交互影響過多導致不容易解釋 ## Sequential Backward Selection - 運用模型好壞判斷哪些特徵需要從特徵集中剔除掉 - Objective Function:用來判斷模型好壞藉以決定哪個特徵需要剔除的函數 - 演算法 - Step1. 決定 Objective Function、模型種類、所有想要納入挑選的特徵,以及設定最終想要有幾個特徵 - Step2. 使用所有挑選的特徵建立模型 - Step3. 輪流扣除一個特徵後,再次建立模型,並運用 Objective Function 計算模型效能 - Step4. 根據模型評估結果,挑選最佳特徵組合 - Step5. 重複 Step3、Step4,直到剩下指定特徵數的特徵   - 優點:觀念簡單、操作容易 - 缺點:容易忽略掉特定特徵組合、變異多 ## 其他有關選擇演算法的變形 - Sequential Forward Selection - 與 Sequential Backward Selection 完全相反,從一開始只有一個特徵,到最後擁有指定數量的特徵 - 優點、缺點與 Sequential Forward Selection 相似。 - Sequential Floating Forward Selection - 在選入特徵的過程中,插入一次或數次移除已被選入的特徵的判斷,增加特徵組合的數量以達到更大的模型效能  - Sequential Floating Backward Selection - 與 Sequential Floating Forward Selection 剛好相反,在某一次排除特徵的過程中,插入一次或數次加入已被排除的特徵的判斷。 ## Reference Raschka S. [Sebastian Raschka] (2022, January 28). 13.4.4 Sequential Feature Selection (L13: Feature Selection) [Video]. Youtube. https://www.youtube.com/watch?v=0vCXcGJg5Bo Joe Bemister-Buffington, Alex J. Wolf, Sebastian Raschka, and Leslie A. Kuhn (2020) Machine Learning to Identify Flexibility Signatures of Class A GPCR Inhibition Biomolecules 2020, 10, 454. (https://www.mdpi.com/2218-273X/10/3/454#)