【QA】Deep Deterministic Policy Gradient (DDPG) 是什麼?
DDPG是之前強化學習的演算法觀念衍生,融合了Actor-Critic與DQN而演化來的演算法,一樣是有兩個網路,Critic計算動作的好壞,Actor根據Critic網路調整參數獲得更好的策略。接下來我想跟大家分享這個強化學習中屬於進階的演算法。
回答列表
-
2021/09/22 下午 08:57Chili贊同數:0不贊同數:0留言數:0
* 什麼是Deterministic Policy Gradient(DPG): DDPG是model free、off-policy的一種,同樣使用了深度神經網絡用於函數近似。但與Deep Q-learning Network不同的是,DQN只能解決離散且維度不高的action 問題,而DDPG可以解決連續動作空間問題。 另外,DDPG是Actor-Critic方法,有Value Network(critic),又有Policy Network(actor)。 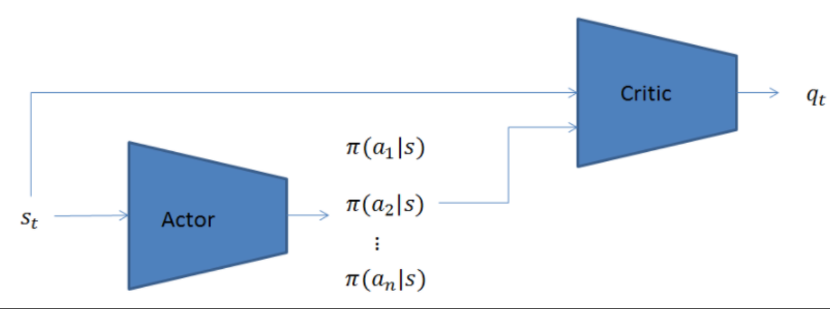 [圖片來源](https://www.wpgdadatong.com/tw/blog/detail?BID=B2541) 差別在於此處引用了兩個網路(target與now),這個Target Network概念源自於Double DQN,因為在DQN中發現一值更新同一個網路容易造成不穩定的現象,因此提出再創造一個網路(target)然後賦予相同的參數值,然後更新參數的時候更新原本的網路即可(now),等訓練一段時間後再把現now網路的參數再賦予給target網路,這麼做可以使得訓練更穩定 --- DDPG也引進Replay Buffer(經驗回放)這概念(源於DQN網路),在訓練的過程中會持續的收集經驗,並且會設定一個buffer size,這個值代表要收集多少筆經驗,每當經驗庫滿了之後,每多一個經驗則最先收集到的經驗就會被丟棄,因此可以讓經驗庫一值保持滿的狀態並且避免無限制的收集資料造成電腦記憶體塞滿。 學習的時候則是從這個經驗庫中隨機抽取成群(batch)經驗來訓練DDPG網路,周而復始的不斷進行學習最終網路就能達到收斂狀態, * 演算法架構圖 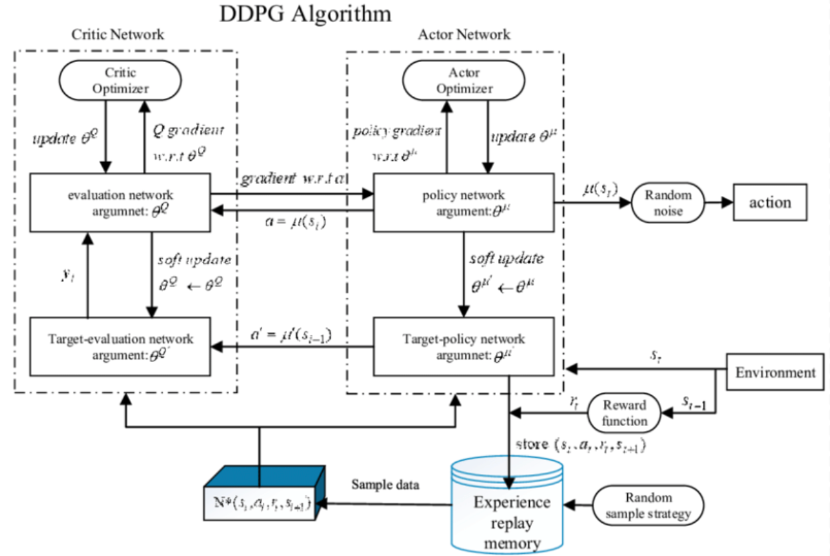 [圖片來源](https://www.wpgdadatong.com/tw/blog/detail?BID=B2541) --- 值得一提的是DQN與DDPG等演算法都有使用target network觀念,只DQN中的target network更新是hard update,即每隔固定步數更新一次target網絡;DDPG 的target network更新使用soft update,每一步都會更新target網絡,只不過更新的幅度非常小。 ---- 要詳細了解Double DQN、DDPG可以參考這文章與影片: https://hackmd.io/@shaoeChen/SkRbRFBvH https://www.youtube.com/watch?v=O79Ic8XBzvw&list=PLJV_el3uVTsPMxPbjeX7PicgWbY7F8wW9&index=24 Target Network 、Replay Buffer概念可以參考這裡: https://hackmd.io/@shaoeChen/Bywb8YLKS/https%3A%2F%2Fhackmd.io%2F%40shaoeChen%2FSyqVopoYr 其他參考資料: https://www.wpgdadatong.com/tw/blog/detail?BID=B2541