【QA】Q-learning 中的Epsilon greedy strategy 是什麼?
在強化學習Q-learning演算法中有兩個很重要的概念,且模型需要在這兩個觀念間做取捨,才能更有效地幫助模型訓練,這兩個概念分別是Exploiting & Exploration,接下來我想跟大家討論這兩個概念。
回答列表
-
2021/09/22 下午 08:32Chili贊同數:0不贊同數:0留言數:0
* Exploration vs. Exploitation: 1. Exploration比較好理解就是找尋新的行為,踩點的概念。 2. Exploitation就是根據過去的經驗,找最合適的行為。 用生活例子來說: 每天都去找新的餐廳吃飯,就是Exploration;根據過去吃過的餐廳,來決定晚上要去哪家餐廳吃,就是Exploitation。 * 那為什麼這兩個概念在Q-learning 中很重要呢? 大家還記得Q表的起始值都是0嗎? 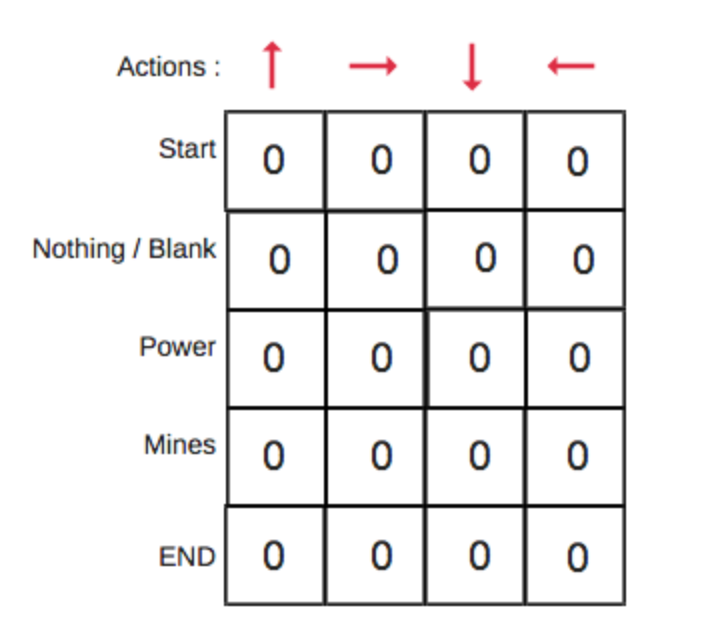 [圖片來源](https://www.freecodecamp.org/news/an-introduction-to-q-learning-reinforcement-learning-14ac0b4493cc/) 因此,當值都是0的時候我們就希望模型做Exploration的動作,去探索未知的領域會帶來怎麼的回饋。否則模型只根據起始值為0的Q表做Exploitation時,並不會有任何結果。 因此才需要模型在Exploration與Exploitation間適當的作轉換,讓模型能有好的訓練結果。 * 該如何做呢? 在Q-learning 中有一個最簡單的應用方法,稱為Epsilon Greedy。  [圖片來源](https://hackmd.io/@shaoeChen/Bywb8YLKS/https%3A%2F%2Fhackmd.io%2F%40shaoeChen%2FSyqVopoYr) 我們首先會設置一個ϵ,通常是一個很小的值,其中有1−ϵ的機率是採argmax的方式執行,選擇Q表中顯示最理想的行為,那有ϵ的機率採隨機行為,完全不理會Q表的結果。 實作上ϵ會隨著時間遞減,因為一開始還不是那麼確定怎麼樣的action是好的,因此隨著時間增長遞減,也就是說,一開始隨機的行為會比較多(Exploration),隨時間推移,漸漸地會根據Q表做決策(Exploitation)。 因此,透過調整ϵ,讓模型做到Exploration與Exploitation間的轉換,讓模型可以訓練出更好的結果。 ---- 參考資料: https://www.freecodecamp.org/news/a-brief-introduction-to-reinforcement-learning-7799af5840db/ https://hackmd.io/@shaoeChen/Bywb8YLKS/https%3A%2F%2Fhackmd.io%2F%40shaoeChen%2FSyqVopoYr