【QA】什麼是強化學習中的Q learning演算法?
增強學習 (Reinforcement learning) 是一種機器學習方法,而 Q-learning 是增強學習中一個最知名的演算法,我想跟大家討論一下Q-learning 的概述。
回答列表
-
2021/09/22 下午 08:18Chili贊同數:0不贊同數:0留言數:0
* What is Q-learning ? Q-learning 是強化學習的一種方法,主要是透過記錄學習過的策略,來告訴智能體(Agent),什麼情況下要對應採取什麼行動(Action)會得到最大的講獎勵(Reward)。Q-learning 最基本的應用方式,就是將對應行動的獎勵值存在一個Q表中(Q-table)。 (但這種方式受限於狀態與動作的數目,不適用於連續的動作中) --- * Q-table Q-table 簡單來說就是一個查詢表,用來計算某狀態下做某行為後未來可以期望得到最大的Reward為多少。這個表可以以倒我們選出每個狀態(state)下,最好的行為(Action)。 ---- * 如何計算Q table 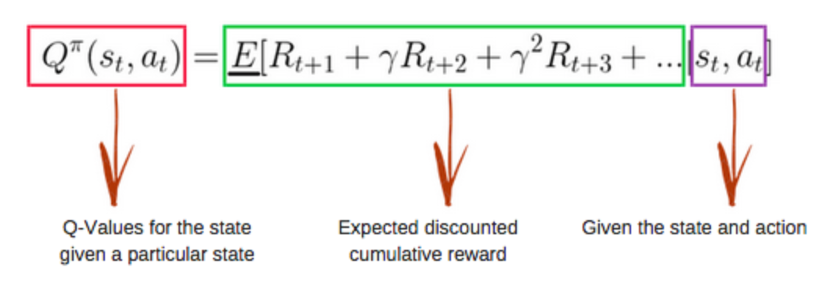 [圖片來源](https://hackmd.io/@shaoeChen/Bywb8YLKS/https%3A%2F%2Fhackmd.io%2F%40shaoeChen%2FSyqVopoYr) 用上面的方程式,可以計算出表中每一個Q值。 (如果想要了解Q-learning演算法,可以看這篇文章的說明:https://hackmd.io/@shaoeChen/Bywb8YLKS/https%3A%2F%2Fhackmd.io%2F%40shaoeChen%2FSyqVopoYr) --- # 演算法步驟 * 初始化Q table: 先建立一個Q表,Action數量為表中的Column數,State數量則為Row數,一開始的值皆為0。 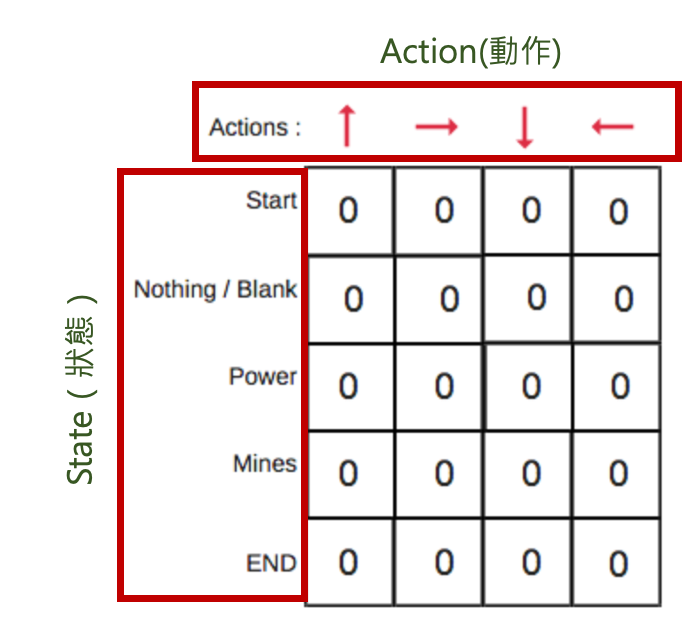 [圖片來源](https://www.freecodecamp.org/news/an-introduction-to-q-learning-reinforcement-learning-14ac0b4493cc/) * 選擇與執行某個Action: 我們根據Q表,選擇一個Action配上State。 (既然一開始值皆為0,我們一開始就需要模型自己先探索和發現,行動的Reward會是多少,這個探索的觀念我們稱為Epsilon Greedy Strategy) (更多關於Epsilon Greedy Strategy可以看另一個問題:https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017C0D77576F0000002A6375706F795F72656C656173655155455354) 在一開始,我們會盡量讓模型自己先不要依據Q表做決定,先隨機採取行動,並評估Reward,通過調高Epsilon比率,來讓模型多做探索的工作。 直到後面資料筆數夠多後,我們可以透過降低Epsilon比率,讓模型可以依據Q表的紀錄,來採取會產生最多Reward的行為。 --- * 評估與更新: 我們採取某行動,觀察其結果與獎勵(Reward)後,我們透過下面這個方程式來更新Q值。  [圖片來源](https://www.freecodecamp.org/news/an-introduction-to-q-learning-reinforcement-learning-14ac0b4493cc/) 此演算法簡單的蓋念為利用過去與最近的權重平均來迭代更新數值。 其中R(s,a)表示獎勵值,其中 α為學習率(0<α≤1),γ為衰減系數(0≤γ≤1),當 γ數值越大時,Agent便更加重視未來獲得的長期獎勵, γ數值越小時,Agent便更加短視近利,只在乎目前可獲得的獎勵。 ---- 參考資料: https://hackmd.io/@shaoeChen/Bywb8YLKS/https%3A%2F%2Fhackmd.io%2F%40shaoeChen%2FSyqVopoYr https://www.freecodecamp.org/news/an-introduction-to-q-learning-reinforcement-learning-14ac0b4493cc/ https://www.youtube.com/watch?v=HTZ5xn12AL4