【QA】LSTM 和 GRU 模型的差異為何?
在自然語言處理和序列相關的深度學習領域中,常會遇到 LSTM 和 GRU 模型選擇的問題,究竟他們的差異在哪,甚麼情況該使用哪個模型呢?以下提供統整
回答列表
-
2021/09/21 下午 06:45Tim贊同數:0不贊同數:0留言數:0
## 共通處 LSTM 和 GRU 的機制,即解決 RNN 梯度爆炸及梯度消失,及其對長期記憶丟失的問題 ## 相異處 簡單來說,GRU 可以看成簡化版的 LSTM,兩者最大的相異之處即 1. GATE 數量 2. GATE 的作用 3. 是否引入 memory cell 以下簡介 LSTM 和 GRU 模型中 GATE 的數量和作用: ### LSTM 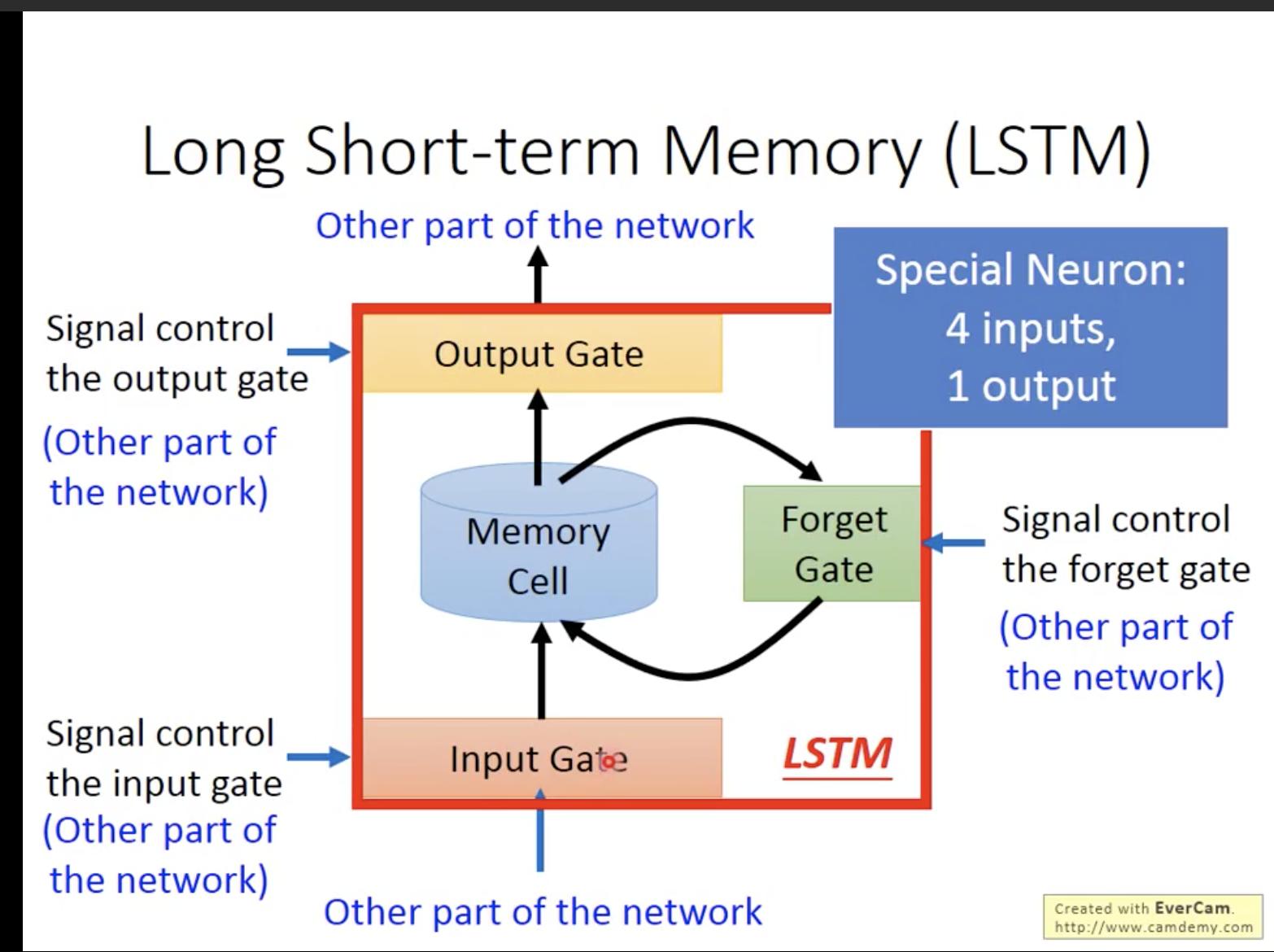 Memory cell,即 c(t),用於儲存長期資訊,而模型包含三個 GATE: * Input gate:負責控管新資訊,即 x(t) 和 h(t-1),有多少比例被寫進 c(t) * Output gate:決定從 c(t) 讀取多少比例,來計算 hidden state h(t) * forget gate:控管多少比例的 c(t-1) 要被保留到 c(t) ### GRU 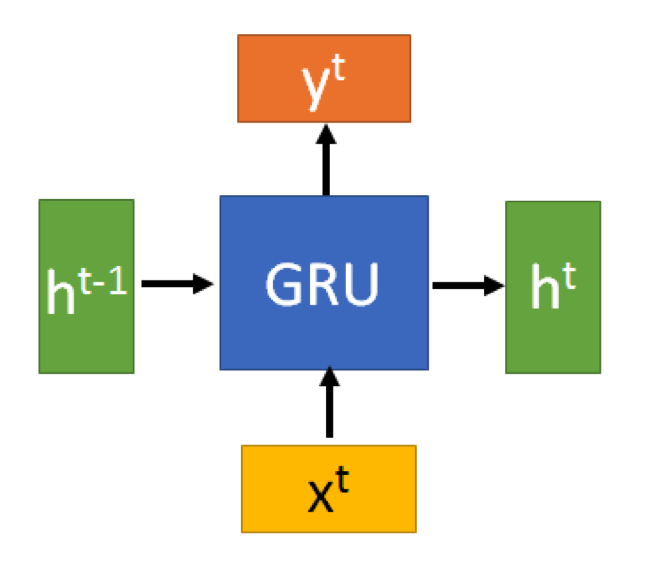 和 LSTM 不同的是,GRU 沒有 Memory cell 的機制,且只用了兩個 GATE, * Reset gate:控管多少比例的 h(t-1) 來和 x(t) 一起計算「準」h(t) * Update gate:控管「準」h(t) 和 h(t-1) 的比例,來計算最終的 h(t) ## 結論 在選擇模型時,LSTM 會是最佳選擇,但 GRU 因為比 LSTM 少使用一個 GATE,參數較少,在運算上較 LSTM 快速,且模型表現和 LSTM 差不多,所以在考慮計算能力和時間成本的情況下,多數會使用 GRU 模型 -------- 參考: [LSTM 與 GRU 架構與歸納](https://zh-tw.coderbridge.com/series/2ec9cf0af3f74ed99371952f4849ae33/posts/2be54d939e0249f392eba159e5126e0b) [人人都能看懂的GRU](https://zhuanlan.zhihu.com/p/32481747)