【QA】欠採樣(Undersampling)的常用技術-NearMiss、Tomek Link、Edited Nearest Neighbours(ENN)?
繼上次介紹在[【QA】欠採樣(Undersampling)的常用技術-隨機欠採樣、Easyensemble、BalanceCascade??](https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017BEEF59488000000196375706F795F72656C656173655155455354)就介紹過歉採樣中的隨機欠採樣、Easyensemble、BalanceCascade等常用技術,接下來要繼續介紹NearMiss、Tomek Link、Edited Nearest Neighbours(ENN)等欠採樣常用技術
回答列表
-
2021/09/18 上午 03:10Ray贊同數:0不贊同數:0留言數:0
本次我們要來繼續介紹上次在[【QA】欠採樣(Undersampling)的常用技術-隨機欠採樣、Easyensemble、BalanceCascade??](https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017BEEF59488000000196375706F795F72656C656173655155455354)中沒能介紹到的常用技術: 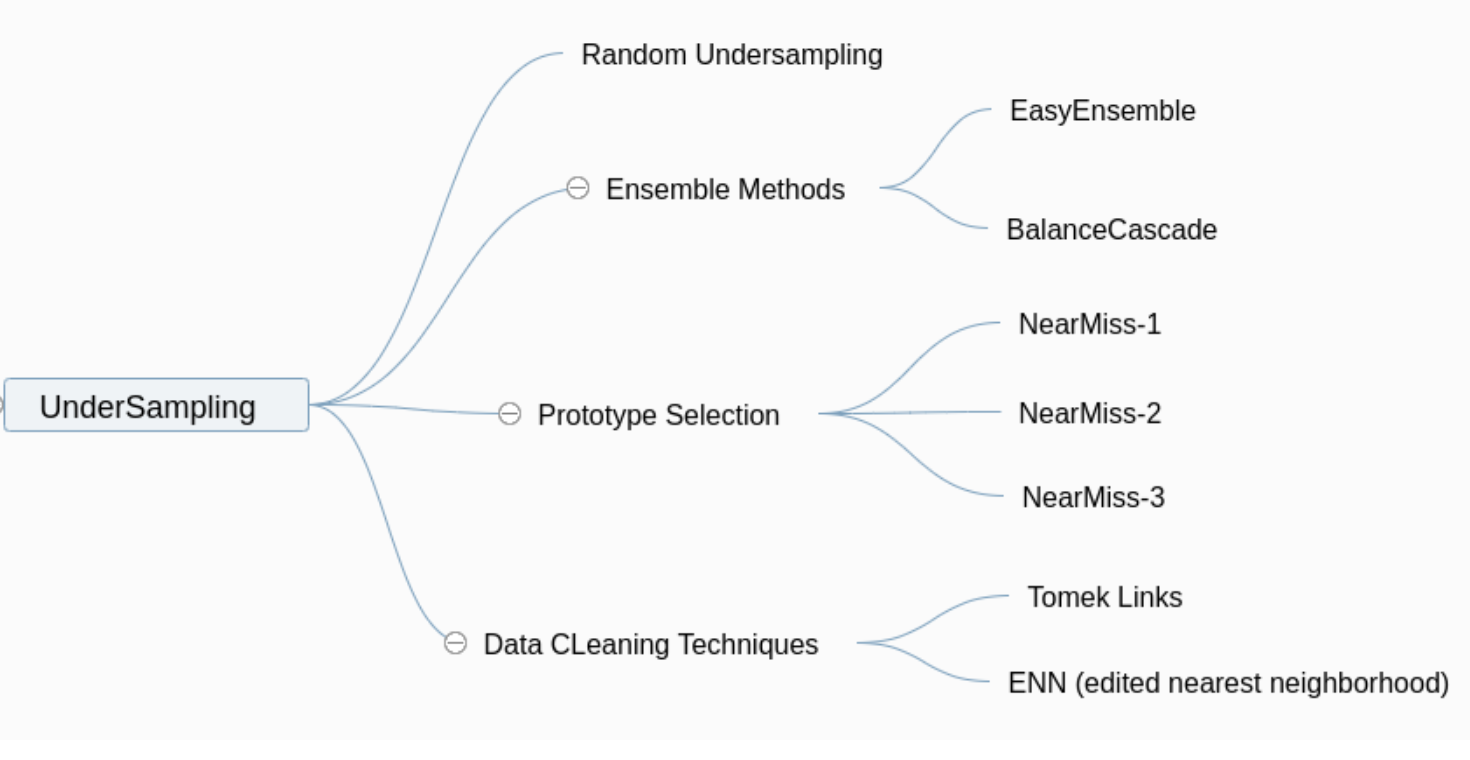[參考圖片來源](https://www.cnblogs.com/massquantity/p/9382710.html) 1. Prototype Selection(原型選擇):原型選擇的主要方法就是NearMIss,NearMiss同樣是作為隨機欠取樣的一種衍生,它主要是為了減緩隨機欠取樣中的重要資訊容易丟失的問題,其概念是通過啟發式的規則從多數類別的樣本中選擇具有代表性的樣本進行訓練,而根據NearMiss的規則不同可分為3類: 1. NearMiss-1:分別計算每個多數類別樣本與每個少數類樣本之間的距離,之後選擇最近的 k 個少數類別樣本並計算這 k 個少數類別樣本與該多數類別樣本之間的平均距離,最後進行比較,保留平均距離最小的多數類別樣本。 以下圖為例: 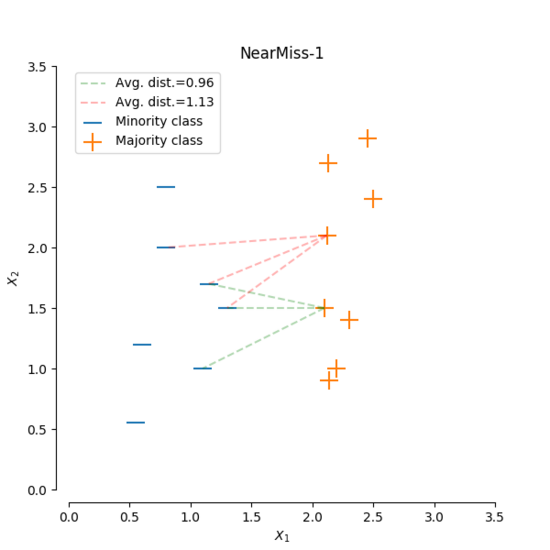[參考圖片來源](https://www.gushiciku.cn/pl/2LNL/zh-tw) +代表多數類別,-代表少數類別,假設k=3 ,計算多數類別中的兩個樣本到最近的三個少數類別樣本的平均距離。通過計算可以發現綠線的距離比紅線的距離小,也就是說綠線對應的樣本到最近的3個少數類別樣本的平均距離比紅線對應的樣本的平均距離小,因此最後保留綠線對應的多數類樣本。 2. NearMiss-2:與NearMiss-1剛好相反,NearMiss-2是分別計算每個多數類別樣本與每個少數類樣本之間的距離,之後選擇最遠的 k 個少數類別樣本並計算這 k 個少數類別樣本與該多數類別樣本之間的平均距離,最後進行比較,保留平均距離最小的多數類別樣本。 以下圖為例: 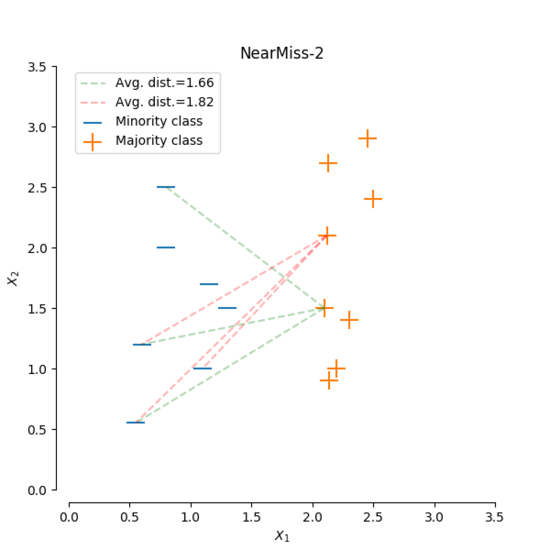[參考圖片來源](https://www.gushiciku.cn/pl/2LNL/zh-tw) 方法同上,同樣假設k=3,計算多數類別中的兩個具體樣本的距離。通過計算可以發現綠線的距離比紅線的距離小,即綠線對應的多數類別樣本到最遠的3個少數類別樣本的平均距離距離比紅線所對應的多數類別樣本小,因此我們選擇綠線對應的多數類樣本。 3. NearMiss-3:分別計算每個少數類別樣本與每個多數類別樣本之間的距離,保留距離最近的k個多數類別樣本,以保證每個少數類別樣本都被多數類別樣本包圍。 以下圖為例: 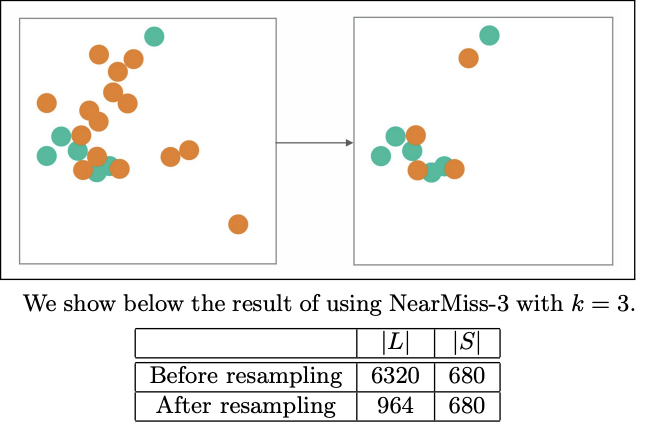[參考圖片來源](https://arxiv.org/pdf/1608.06048.pdf) 同樣假設k=3,分別計算每個多數類別樣本與每個少數類別樣本之間的距離,並保留對於每個少數類別樣本來說最近的3個多數類別樣本。 ---------------- 2. Tomek Links:Tomek Link表示不同類別之間距離最近的一對樣本,即兩個樣本之間互為最近鄰且分屬不同的類別,如此這兩個樣本就形成了一個Tomek Link,Tomek Link中的兩個樣本可能其中一個是噪音或雜訊,也可能是兩個樣本都在邊界附近。通過移除Tomek Link能夠刪除不同類別之間相互重疊的樣本,使得互為最近鄰的樣本皆屬於同一類別,進而更好地進行分類。 以下圖為例: 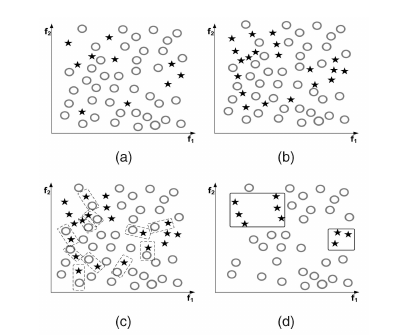[參考圖片來源](https://www.cnblogs.com/massquantity/p/9382710.html) 上圖中 (a) 為原始資料集, (b) 為經過 SMOTE 演算法過取樣後的資料, (c) 中虛線框住的樣本表示的是 TomekLinks , (d) 則是移除 TomekLinks 後的結果圖。可以發現從 (b) 到 (d) 不同類別之間樣本重疊的情況減少了許多,樣本的分類變得更加簡單。 -------------- 3. ENN(Edited Nearest Neighborhood):對於每一個多數類別樣本,如果其K個近鄰點有超過一半(或著是全部)都不屬於多數類別,則這個樣本就會被刪除。 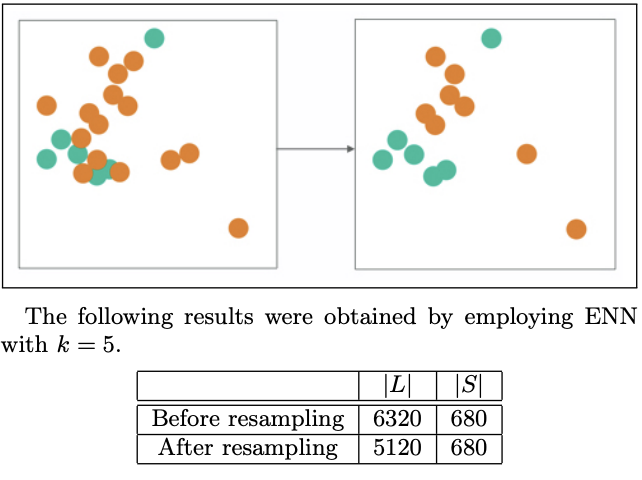[參考圖片來源](https://arxiv.org/pdf/1608.06048.pdf) --------------------- 有興趣的人可以參考以下連結: * [Survey of resampling techniques for improving classification performance in unbalanced datasets](https://arxiv.org/pdf/1608.06048.pdf) * [不平衡数据分类算法介绍与比较](https://blog.csdn.net/a358463121/article/details/52304670) * [機器學習之類別不平衡問題:從資料集角度處理不平衡問題(二)](https://www.gushiciku.cn/pl/2LNL/zh-tw) * [机器学习之类别不平衡问题 (3) —— 采样方法](https://www.cnblogs.com/massquantity/p/9382710.html)