【QA】欠採樣(Undersampling)的常用技術-隨機欠採樣、Easyensemble、BalanceCascade??
在介紹過不平衡數據的過採樣處理方法後[【QA】過採樣(oversampling)的常用技術??](https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017BD8FC94950000000A6375706F795F72656C656173655155455354),接著將要與各位一起探討另外一部分的不平衡數據處理方法-欠採樣
回答列表
-
2021/09/17 上午 00:14Ray贊同數:0不贊同數:0留言數:0
我們在[【QA】過採樣(oversampling)的常用技術??](https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017BD8FC94950000000A6375706F795F72656C656173655155455354)與[【QA】過採樣(oversampling)的常用技術-ADASYN、Borderline-SMOTE??](https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017BDED9AEB00000000E6375706F795F72656C656173655155455354)中介紹了過採樣的幾種常用技術,本次要接著來介紹欠採樣的常用技術: 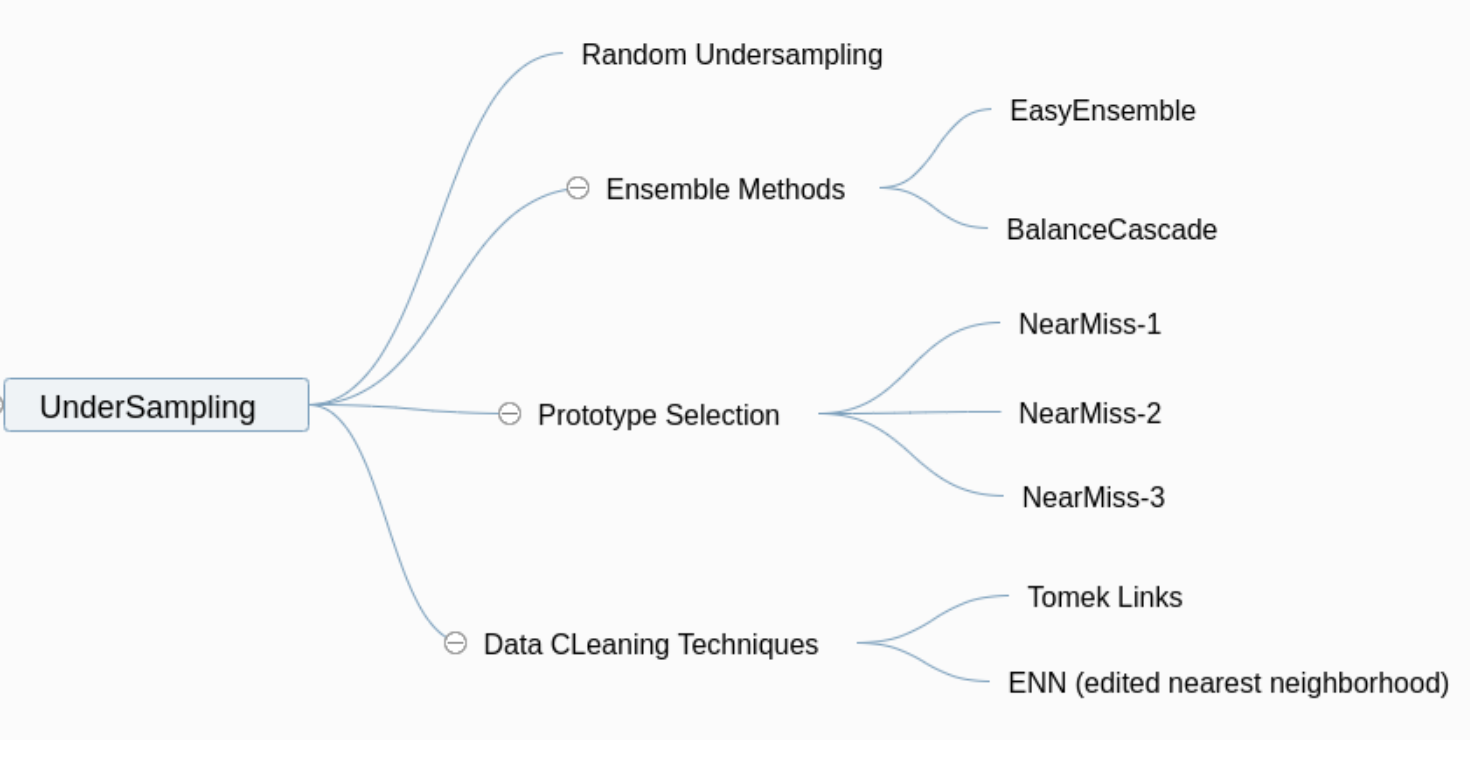[參考圖片來源](https://www.cnblogs.com/massquantity/p/9382710.html) 1. 隨機欠採樣(Random Undersampling):隨機欠採樣與隨機過採樣相同,屬於概念較為簡單的採樣技術,隨機欠採樣的方法就是從多數類別的樣本中隨機刪除一部分的樣本,但是因為是隨機刪除,被刪除的樣本當中可能會含有一些比較重要的樣本,因此訓練出來的模型效果通常較差。 --------------------- 2. 集成式方法:採用集成學習(Ensemble learning)的方法來改善隨機欠採樣中重要樣本被隨機刪除的問題,集成式方法分為兩種: * EasyEnsemble:其概念是將多數類別的樣本隨機劃分成n個子集,每個子集的數量等於少數類樣本的數量,這相當於欠採樣。接著將每個子集與少數類樣本結合起來訓練成若n個分類器進行集成學習,這樣雖然每個子集的樣本少於總體樣本,但集成後總信息量並未減少。 下圖為EasyEnsemble論文中的虛擬碼: [參考圖片來源](https://cs.nju.edu.cn/wujx/paper/icdm06-easyensemble-vfinal.pdf) 根據上圖可以了解到其算法過程如下: 1. 重複對多數類別樣本進行有放回採樣T次,採樣的數量與少數類樣本相同,並將採樣得到的多數類別樣本與少數類別樣本結合形成子集 2. 利用得到的T個子集分別訓練成T個AdaBoost弱分類器 3. 集成T個AdaBoost弱分類器,最後使用sgn函數來進行分類,sgn函數會把非整數的結果轉換成兩個分類,小於0返回-1,大於0則返回1。 * BalanceCascade:BalanceCascad的概念與EasyEnsemble差異不大,同樣是將多數類別的樣本隨機劃分成n個子集,每個子集的數量等於少數類樣本的數量,接著將每個子集與少數類樣本結合起來訓練成若n個分類器進行集成學習,但是BalanceCascad會在這過程中調整閥值,通過調整閥值在每次訓練弱分類器後將正確分類的樣本刪除,只保留下分類錯誤的樣本,以此來控制False Positive Rate(偽陽性率),降低多數類別的樣本數量。 下圖為BalanceCascade論文中的虛擬碼: [參考圖片來源](https://cs.nju.edu.cn/wujx/paper/icdm06-easyensemble-vfinal.pdf) 其算法過程如下: 1. 重複對多數類別樣本進行有放回採樣T次,採樣的數量與少數類樣本相同,並將採樣得到的多數類別樣本與少數類別樣本結合形成子集 2. 利用得到的T個子集分別訓練成T個AdaBoost弱分類器 3. 調整閥值theta以保證False Positive Rate(偽陽性率)等於f 4. 刪除多數類別樣本中被AdaBoost弱分類器正確分類的樣本 5. 將T個AdaBoost弱分類器進行集成,最後使用sgn函數來進行分類。 ----------------------- 有興趣進一步了解的人可以參考以下連結: * [Exploratory Under-Sampling for Class-Imbalance Learning](https://cs.nju.edu.cn/wujx/paper/icdm06-easyensemble-vfinal.pdf) * [机器学习之类别不平衡问题 (3) —— 采样方法](https://www.cnblogs.com/massquantity/p/9382710.html) * [easy ensemble 算法和balance cascade算法](https://blog.csdn.net/march_on/article/details/48656391) * [EasyEnsemble(集成学习——处理不平衡样本分类问题)-附程式碼](https://www.pianshen.com/article/5101161379/) * [非平衡分类问题 | BalanceCascade方法及其Python实现](https://zhuanlan.zhihu.com/p/36093594)