【QA】過採樣(oversampling)的常用技術-ADASYN、Borderline-SMOTE??
由於避免篇幅過長,在上次的[【QA】過採樣(oversampling)的常用技術??](https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017BD8FC94950000000A6375706F795F72656C656173655155455354)未能繼續介紹SMOTE的其他衍生技術,因此本次想要繼續與各位探討一下過採樣(oversampling)的常用技術
回答列表
-
2021/09/14 上午 00:43Ray贊同數:0不贊同數:0留言數:0
上次在[【QA】過採樣(oversampling)的常用技術??](https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017BD8FC94950000000A6375706F795F72656C656173655155455354)我們介紹到了過採樣技術中的隨機過採樣和SMOTE;這次繼續接著介紹另外兩種較為常見的過採樣技術: 1. ADASYN(Adaptive Synthetic Sampling)自適應合成採樣:與SMOTE需要自行設定採樣倍率不同,ADASYN會根據數據集的分佈情況,自動判斷每個少數類別樣本需要合成多少新的樣本。而其ADASYN最大的特點是每個少數類別樣本需要合成多少新樣本是分別決定的,而不是像SMOTE那樣每個少數類樣別本合成的樣本數量都一樣。 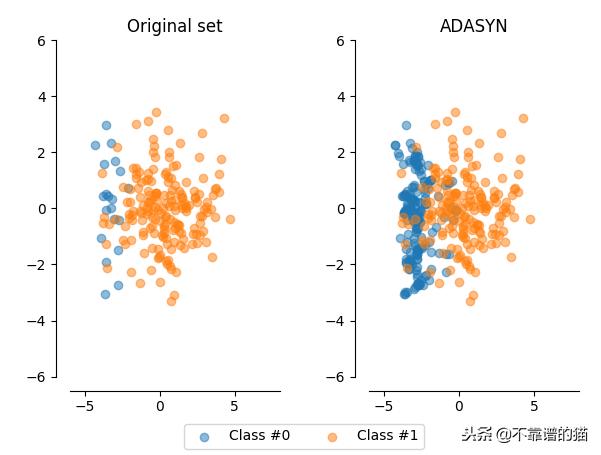[參考圖片來源](https://kknews.cc/zh-tw/code/oaxom4q.html) ADASYN算法如下: 計算需要合成的樣本總量G: 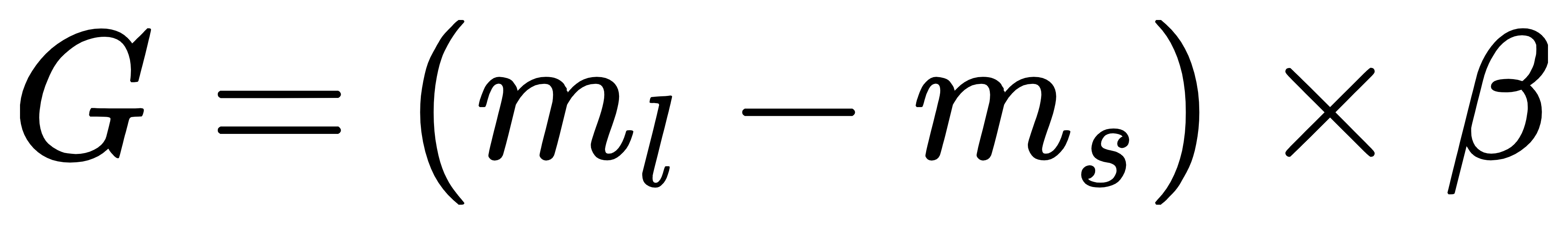 其中ml與ms分別代表多數類樣本數量與少數類樣本數量,delta為控制樣本總量的引數,delta也是一個[0, 1]的隨機因子,當delta=1時採樣後各類別的樣本數量相同,也就是完美平衡的意思 找到每個少數類別的k最近鄰,並計算rᵢ值: 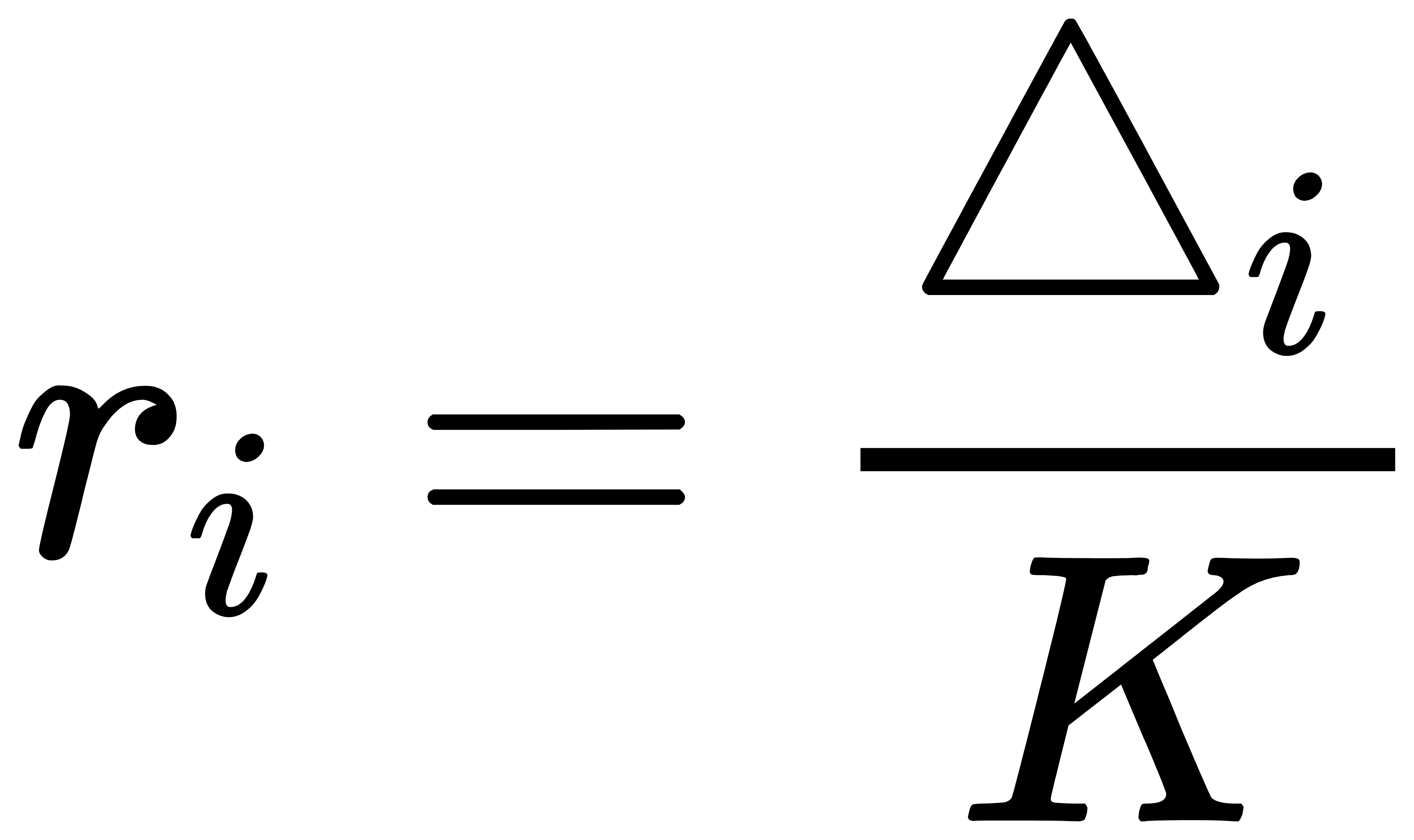 其中三角形i代表的是每個少數類別的k最近鄰中多數類別樣本的數量,i=1,2,3,......,ms 接著對ri進行歸一化(標準化): 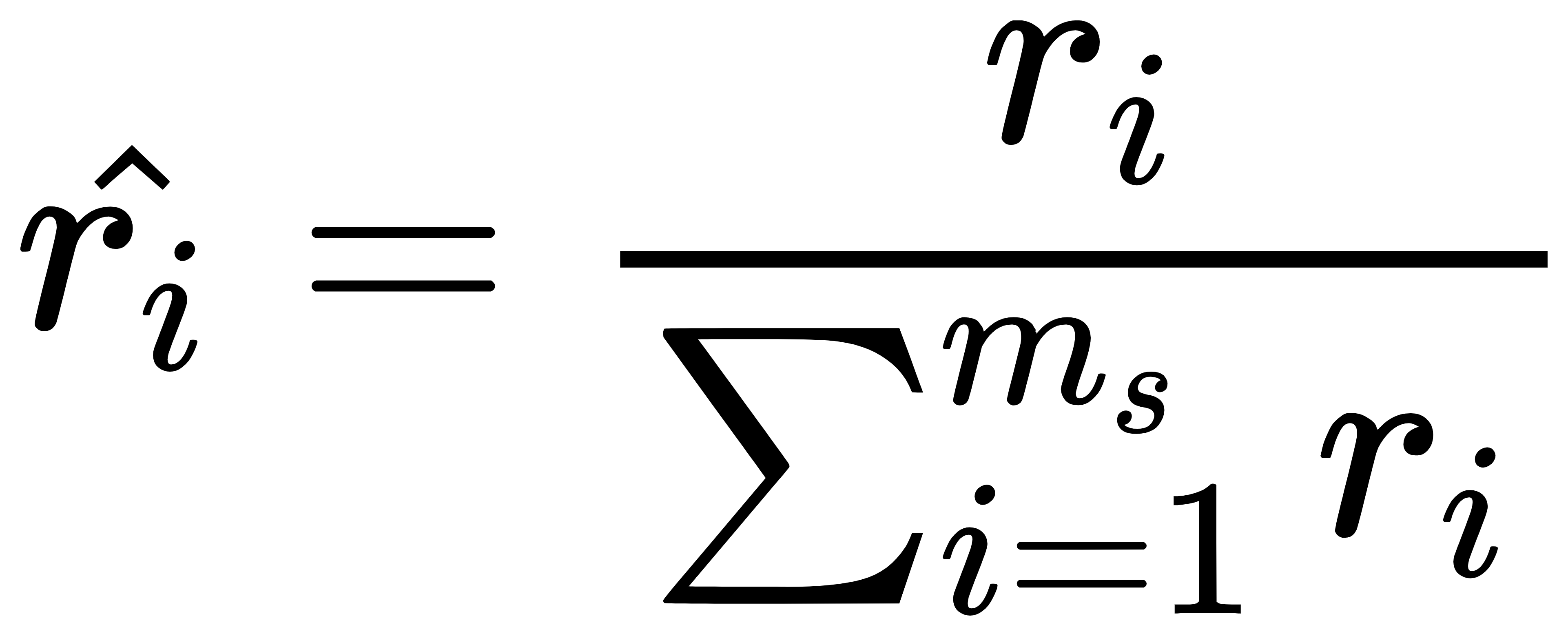 計算每個少數類樣本需合成的數量 : 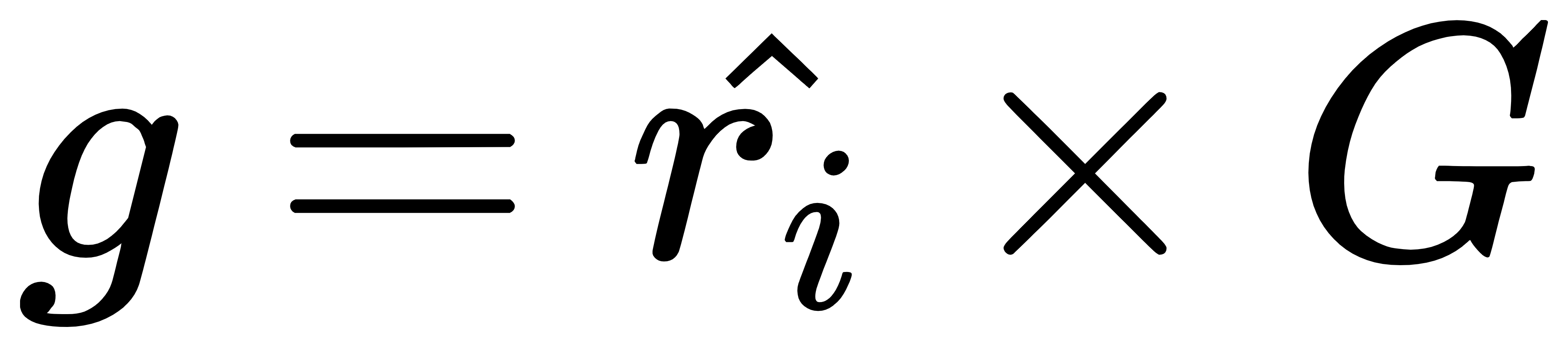 接著再用SMOTE演算法合成新樣本: 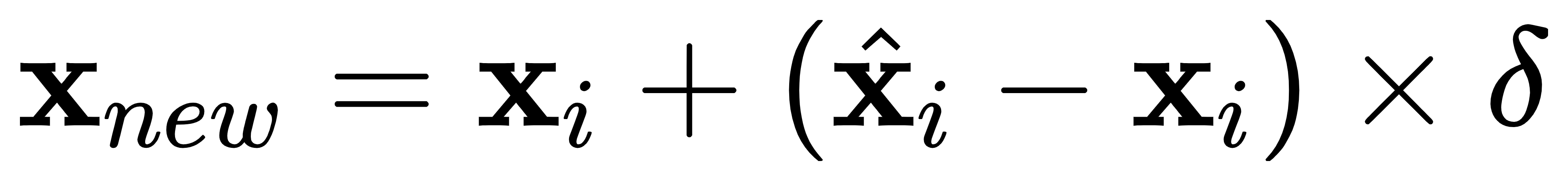 因為這部分在[【QA】過採樣(oversampling)的常用技術??](https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017BD8FC94950000000A6375706F795F72656C656173655155455354)已經介紹過了,因此在此就不多加贅述了 **特點:ADASYN演算法利用分佈情況自動確定每個少數類樣本點需要合成的樣本數量,相當於給每個少數類樣本一個權重,少數類周圍的多數類樣本越多,則其權重也就越大。因此ADASYN演算法的一個明顯的缺點就是容易收到噪聲的影響,從而導致生成的樣本與SMOTE演算法一樣會有類與類之間樣本顯著重疊的問題。** -------------- 2. Border-line SMOTE:Border-line SMOTE的概念是尋找那些處於兩個類別邊界附近的樣本點,並這些樣本點來合成新的樣本,這樣合成的樣本才會提供對模型分類有意義的資訊。 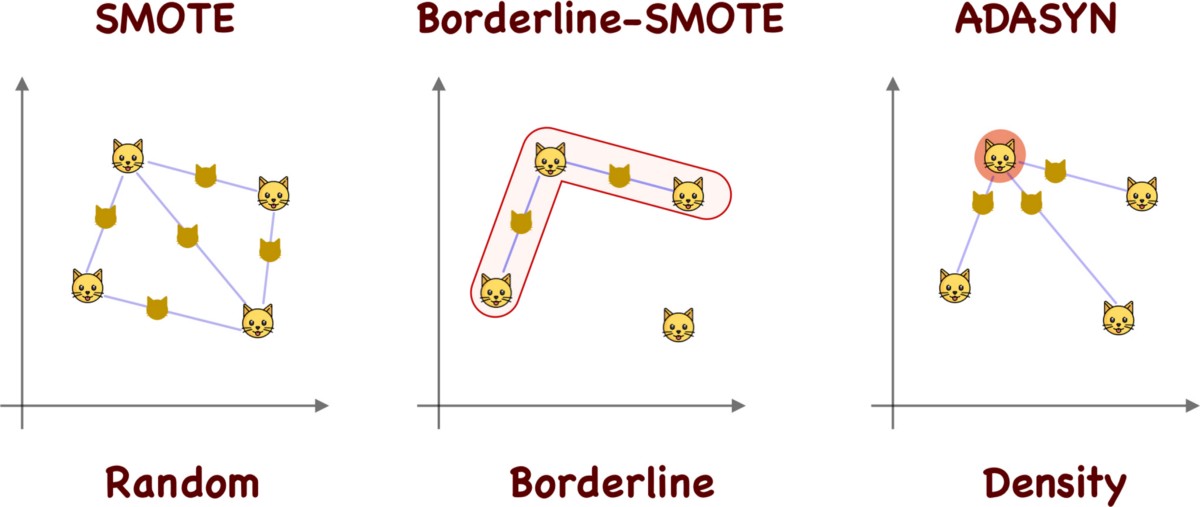[參考圖片來源](https://www.google.com/url?sa=i&url=https%3A%2F%2Ftowardsdatascience.com%2Fsmote-synthetic-data-augmentation-for-tabular-data-1ce28090debc&psig=AOvVaw0WfN1v1xTmfkmDbgsrVSM7&ust=1631636125717000&source=images&cd=vfe&ved=0CAsQjRxqFwoTCMisnrKs_PICFQAAAAAdAAAAABAc) 算法如下: 計算少數類樣本點的k近鄰,按照k近鄰中少數類別樣本的個數比例多少,將樣本分為三種狀態,如下: "noise":大多數的k近鄰個樣本都屬於多數類別樣本; "danger":超過一半的k近鄰樣本屬於多數類別樣本; "safe":超過一半的k近鄰樣本屬於少數類別樣本; 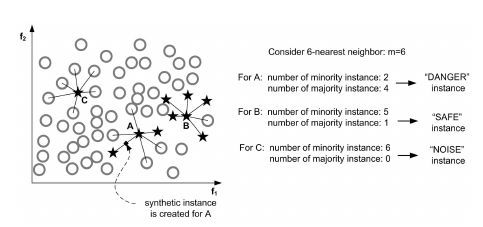[參考圖片來源](https://www.gushiciku.cn/pl/2VGp/zh-tw) 最後只對處於”danger"狀態下的樣本中進行過採樣,處於"danger"狀態下的樣本代表不同類別之間邊界附近的樣本,處於邊界附近的樣本更容易被分錯,也更能提供有意義的資訊,Border-line SMOTE只利用這些樣本來生成新的樣本。而過採樣的方法則是使用SMOTE算法來生成新樣本。 **Borderline-SMOTE又可分為Borderline-SMOTE1、Borderline-SMOTE2以及Border-line SVM三種不同的衍生技術,其中Borderline-SMOTE1在對Danger點生成新樣本時,隨機選擇的k近鄰樣本與該樣本本身處於不同的類別(與SMOTE相同),Borderline-SMOTE2則是隨機選擇在k近鄰中的任意一個樣本(不關注樣本類別),而Border-line SVM SMOTE表示的是使用支援向量機產生支援向量後再生成新的少數類樣本。** ----------------------------- 有興趣進一步了解的人可參考以下連結: * [Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning](https://sci2s.ugr.es/keel/pdf/specific/congreso/han_borderline_smote.pdf) * [ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning](https://www.researchgate.net/publication/224330873_ADASYN_Adaptive_Synthetic_Sampling_Approach_for_Imbalanced_Learning) * [修復不平衡數據集:ADASYN簡介(附完整代碼)](https://kknews.cc/zh-tw/code/oaxom4q.html) * [不平衡数据处理之SMOTE、Borderline SMOTE和ADASYN详解及Python使用](https://blog.csdn.net/u010654299/article/details/103980964) * [機器學習之類別不平衡問題:從資料集角度處理不平衡問題(一)](https://www.gushiciku.cn/pl/2VGp/zh-tw)