【QA】過採樣(oversampling)的常用技術-隨機過採樣、SMOTE?
之前我們在[【QA】什麼是不平衡數據(imbalanced classification problem)?](https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017BD56FDD60000000086375706F795F72656C656173655155455354)中介紹過了什麼是不平衡數據,本次想要進一步跟各位介紹,不平衡數據在數據方面的處理方法--過採樣(oversampling)的常用技術
回答列表
-
2021/09/12 下午 10:28Ray贊同數:0不贊同數:0留言數:0
在[【QA】什麼是不平衡數據(imbalanced classification problem)?](https://www.cupoy.com/qa/club/ai_tw/0000016D6BA22D97000000016375706F795F72656C656173654B5741535354434C5542/0000017BD56FDD60000000086375706F795F72656C656173655155455354)中我們已經大致介紹過過採樣(oversampling)和欠採樣(undersampling)的概念,本次將進一步跟各位介紹過採樣(oversampling)常被使用的技術: 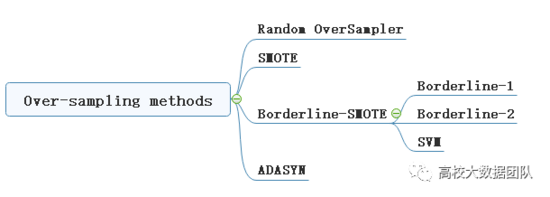[參考圖片來源](https://www.gushiciku.cn/pl/2VGp/zh-tw) 1. 隨機過採樣(Random oversampling):隨機過採樣是最簡單的過採樣技術,顧名思義就是隨機有放回地抽取少數類別的樣本,並將其複製後加入數據集當中。然而這種技術現在已經很少被人們所使用了,因為如果數據的特徵維度較小,簡單的抽取複製容易造成過擬合(over-fitting)。 2. SMOTE (synthetic minority oversampling technique) 少數類過採樣技術:SMOTE是基於隨機過採樣(Random oversampling)技術的一種改進方案,由於隨機過採樣是使用直接複製樣本的策略來增加少數類別的樣本,這樣容易產生模型過擬合的問題,因為模型學習到的信息過於單一特定(Specific)而不夠泛化(General)。 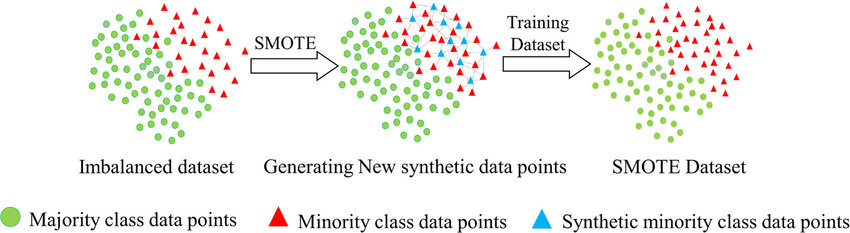[參考圖片來源](https://www.google.com/url?sa=i&url=https%3A%2F%2Fwww.researchgate.net%2Ffigure%2Fllustration-of-synthetic-minority-oversampling-technique_fig2_343326638&psig=AOvVaw2_sYt7_bHK4DRCJC9aUzIC&ust=1631539863668000&source=images&cd=vfe&ved=0CAsQjRxqFwoTCOjDy-PF-fICFQAAAAAdAAAAABAe) SMOTE的基本概念是對少數類樣本進行分析並根據少數類別的樣本來人工合成新樣本並添加到數據集中,其算法如下。 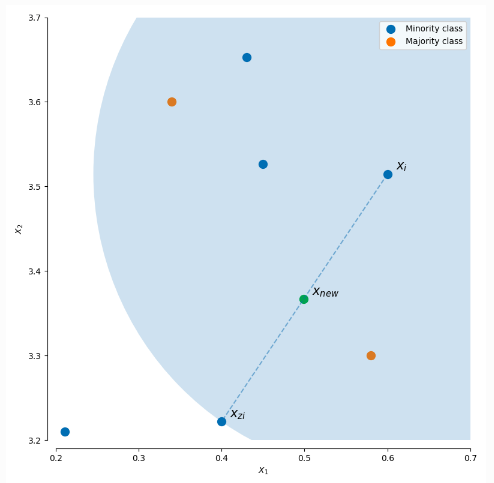[參考圖片來源](https://www.cnblogs.com/massquantity/p/9382710.html) 根據數據的不平衡比例設置一個一個採樣比例以確定採樣倍率N,對於少數類別中每一個樣本x事先設定一個k值,並對樣本x使用k近鄰法,接著以歐氏距離為標準計算它到少數類樣本集中所有樣本的距離,求出離x距離最近的k個少數類別樣本,接著從這k個少數類別樣本中隨機選出一個帶入以下公式: 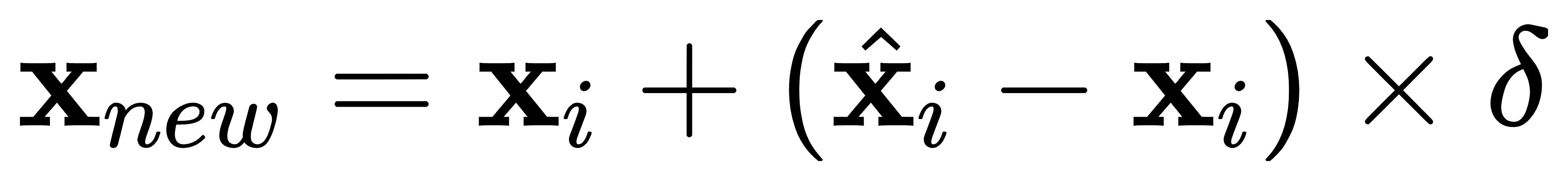 其中delta為一個[0, 1]的隨機因子,x^則是被選到的少數類別樣本 --------------- 在了解SMOTE算法的流程後,接來了解SMOTE的完整流程: 下圖是在SMOTE論文中提出的虛擬碼,該虛擬碼由SMOTE(T, N, K)和Populate(N, i, nnarray)這兩個函式所組成。  基本上過程與我們前面介紹的相同,SMOTE函式負責計算每一個樣本的k個最鄰近點,接著將將每一個最近鄰樣本點的索引存入nnarray;其中N的比例一般為100, 200, 300等以100的倍數,100, 200, 300分別代表1倍,2倍,3倍,而Populate則負責根據nnarray中的索引去隨機生成N個與觀測樣本i相似的樣本。該函式會計算隨機鄰近點nn與觀測樣本i點的每一個特徵之間的差距dif,將其差距乘上一個[0, 1]隨機因子gap,再將dif*gap的值加上觀測點i即完成了一個特徵的合成。 ------- SMOTE會隨機選取少數類樣本用以合成新樣本,而不考慮周邊樣本的情況,這樣容易帶來兩個問題: 1. 如果選取的少數類樣本周圍也都是少數類樣本,則新合成的樣本不會提供太多有用信息。這就像支持向量機中遠離margin的點對決策邊界影響不大。 2. 如果選取的少數類樣本周圍都是多數類樣本,這類的樣本可能是噪音,則新合成的樣本會與周圍的多數類樣本產生大部分重疊,致使分類困難。 ---------------- 有興趣進一步了解的人可以參考以下連結: * [机器学习之类别不平衡问题 (3) —— 采样方法](https://www.cnblogs.com/massquantity/p/9382710.html) * [探索SMOTE演算法](https://iter01.com/480884.html) * [SMOTE: Synthetic Minority Over-sampling Technique](https://www.jair.org/index.php/jair/article/view/10302/24590) * [機器學習之類別不平衡問題:從資料集角度處理不平衡問題(一)](https://www.gushiciku.cn/pl/2VGp/zh-tw)