【QA】正規化(Normalization)為什麼能夠提升機器學習的成效??
本次想要與各位探討一下正規化(Normalization)為什麼能夠提升機器學習的成效
回答列表
-
2021/09/04 下午 09:03Ray贊同數:0不贊同數:0留言數:0
Normalization屬於機器學習中資料預處理的一種技術,資料預處理的技術可分為三種不同的類型:資料清理、資料整合、資料轉換,而normalization則是屬於資料轉換的技術,normalization能夠讓不同維度之間的特徵在數值上有一定的比較性,可以大大提高分類器的準確性。常用的normalization方法有兩種: 1. **_最小值最大值正規化(Min-Max Normalization)_**:Min-Max Normalization是將資料按比例原封不動的縮小至0到1的區間之中 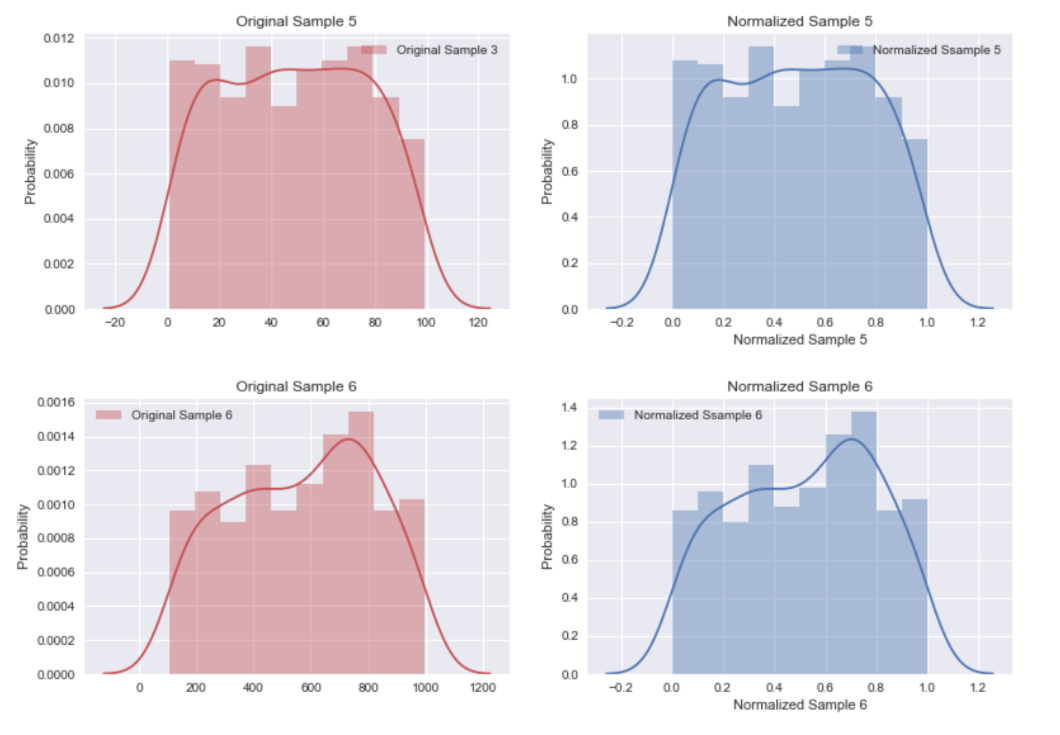[參考圖片來源](https://aifreeblog.herokuapp.com/posts/54/data_science_203/) 其數學式如下圖所示: 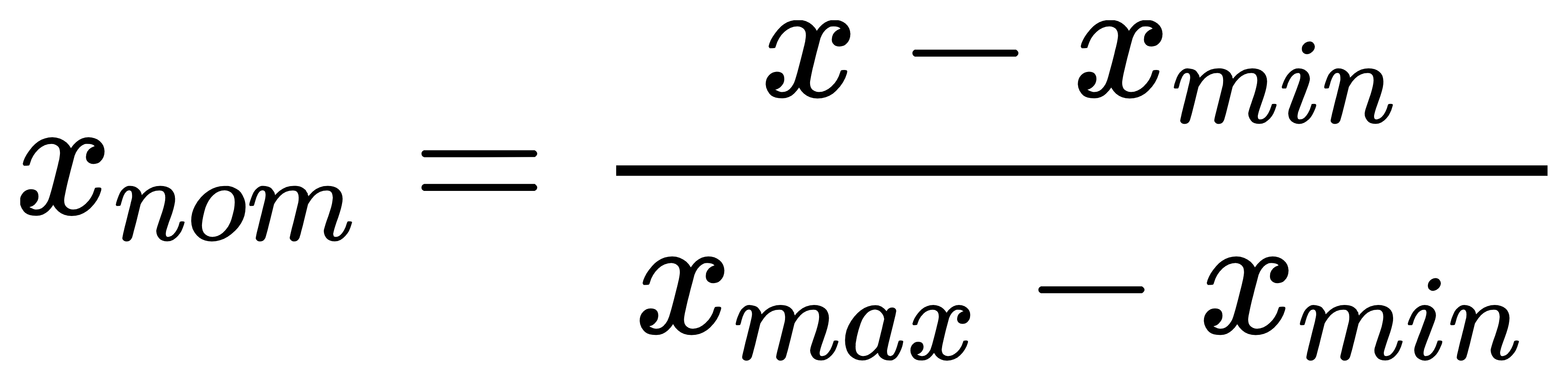 其中Xmin與Xmax為資料的最大值及最小值,最大值與最小值可能會隨著新資料的加入而有所變動,此外,若是將X-Xmin改為X減去資料的平均值的話,就會資料會變成以0為中心大小、範圍為(-1,1)的均值正規化(Mean Normalization),有點類似之前提及的零均值化(Zero Mean) 其程式實現如下圖: 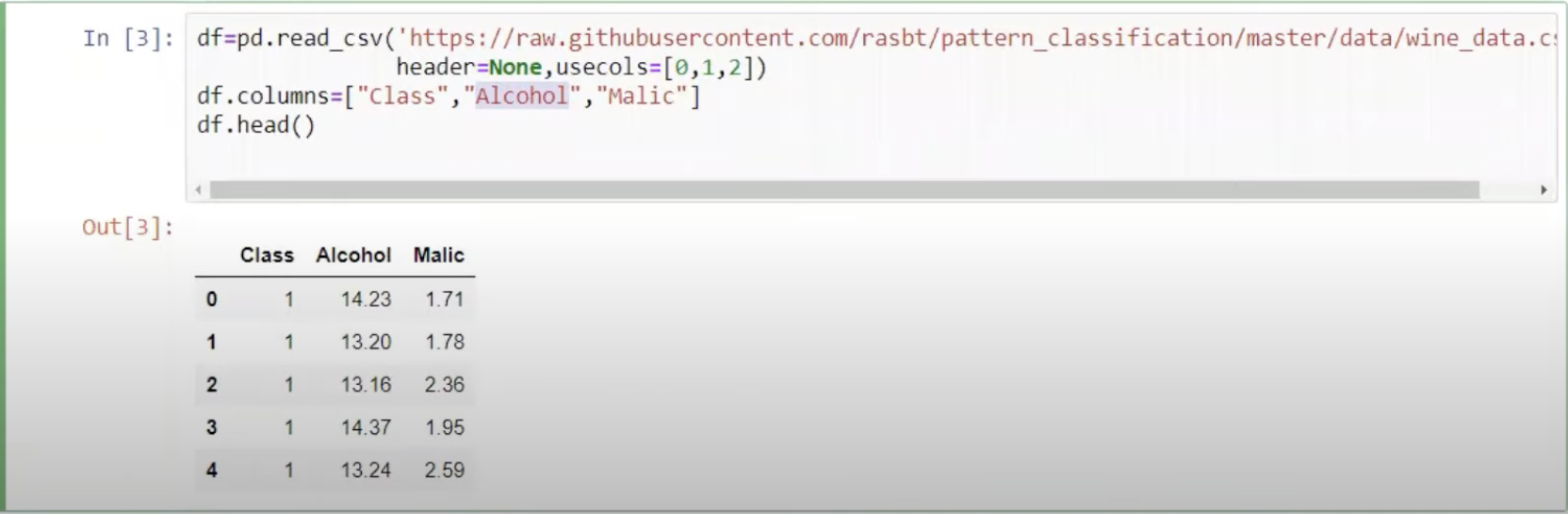[參考圖片來源](https://www.youtube.com/watch?v=mnKm3YP56PY) 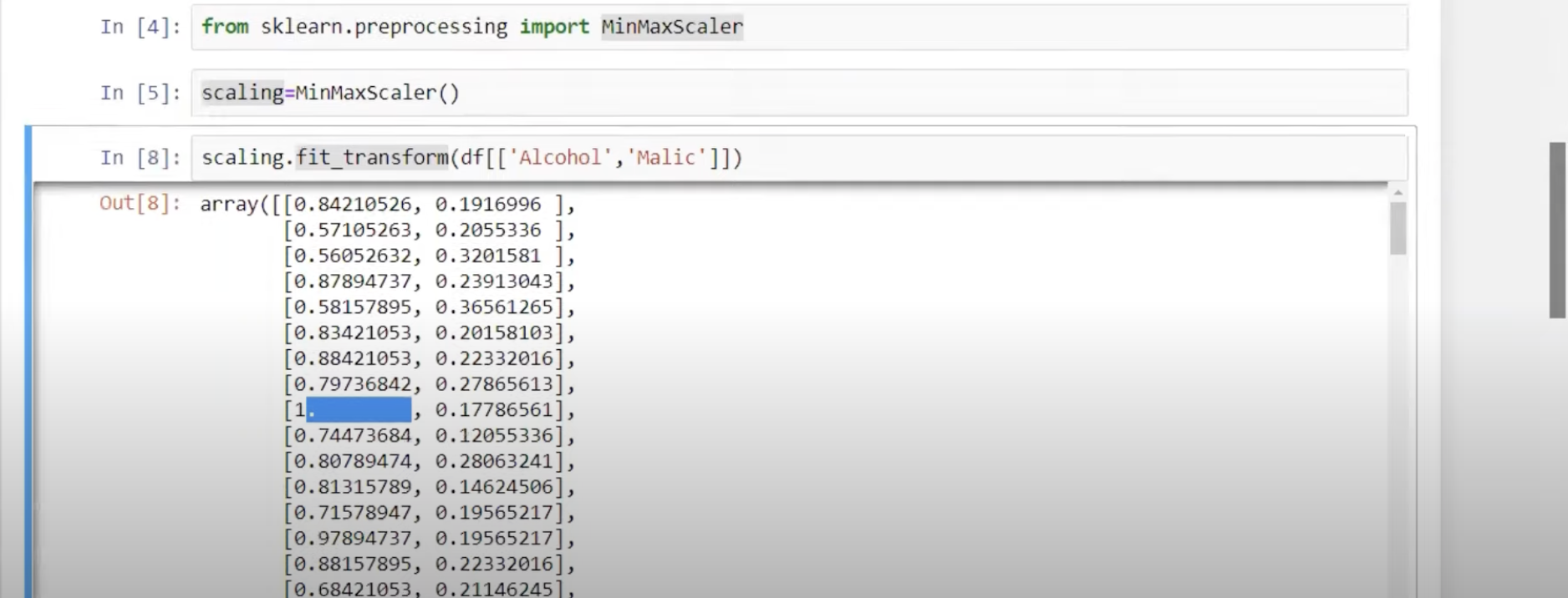[參考圖片來源](https://www.youtube.com/watch?v=mnKm3YP56PY) 2. **_Z分數標準化(Z-Score Normalization)_**:又稱為Standardization,經 Z分數標準化後,資料將符合標準常態分佈(Standard Normal Distribution),也就是資料的平均值為0、標準差為1 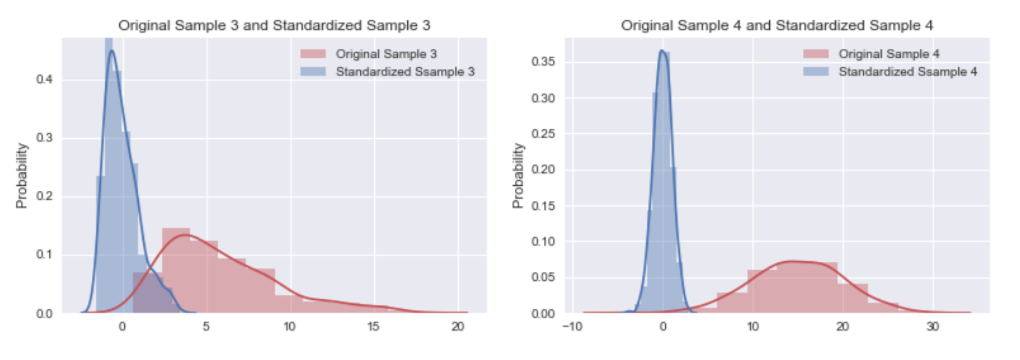[參考圖片來源](https://aifreeblog.herokuapp.com/posts/54/data_science_203/) 其數學式如下圖所示: 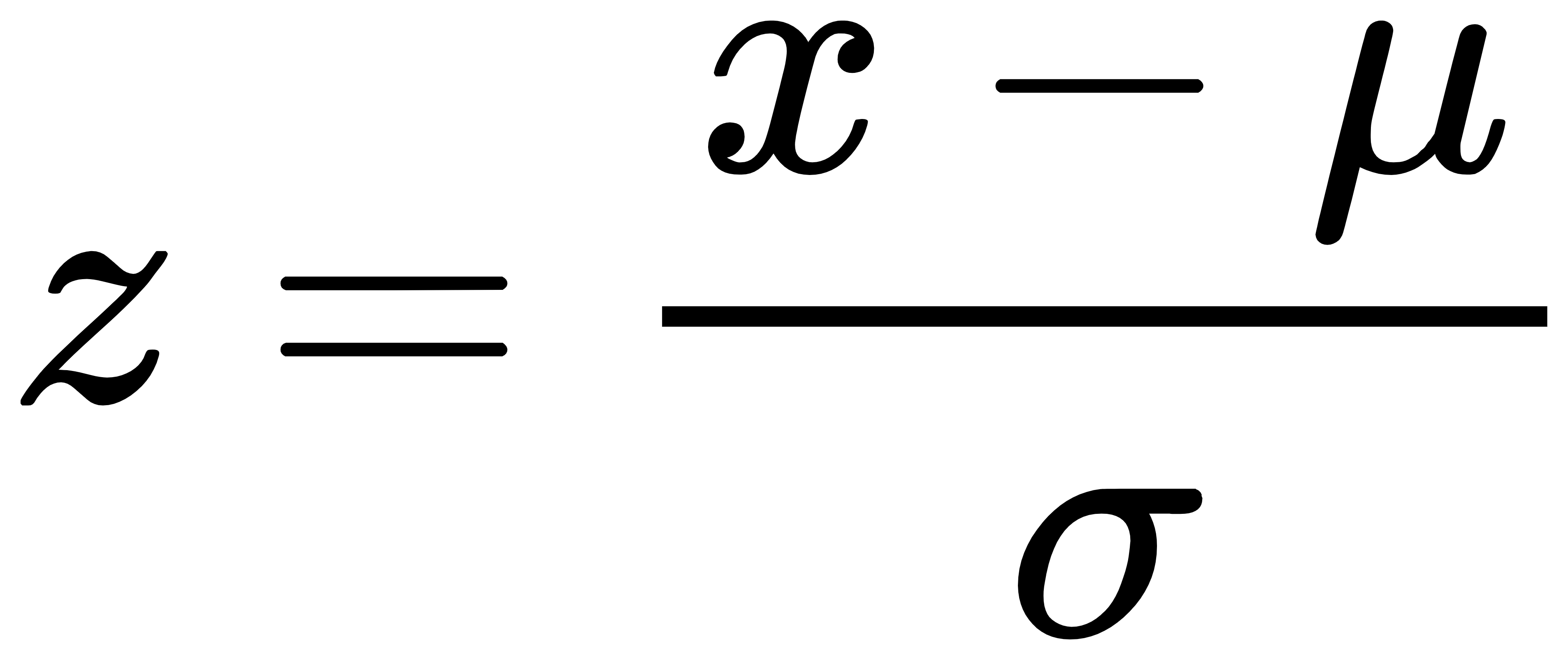 其中mu代表平均值,sigma代表標準差,Standardization適用於特徵分布較為對稱的資料,若是用於分佈過於混亂的資料可能會導致錯誤 其程式實現如下圖: 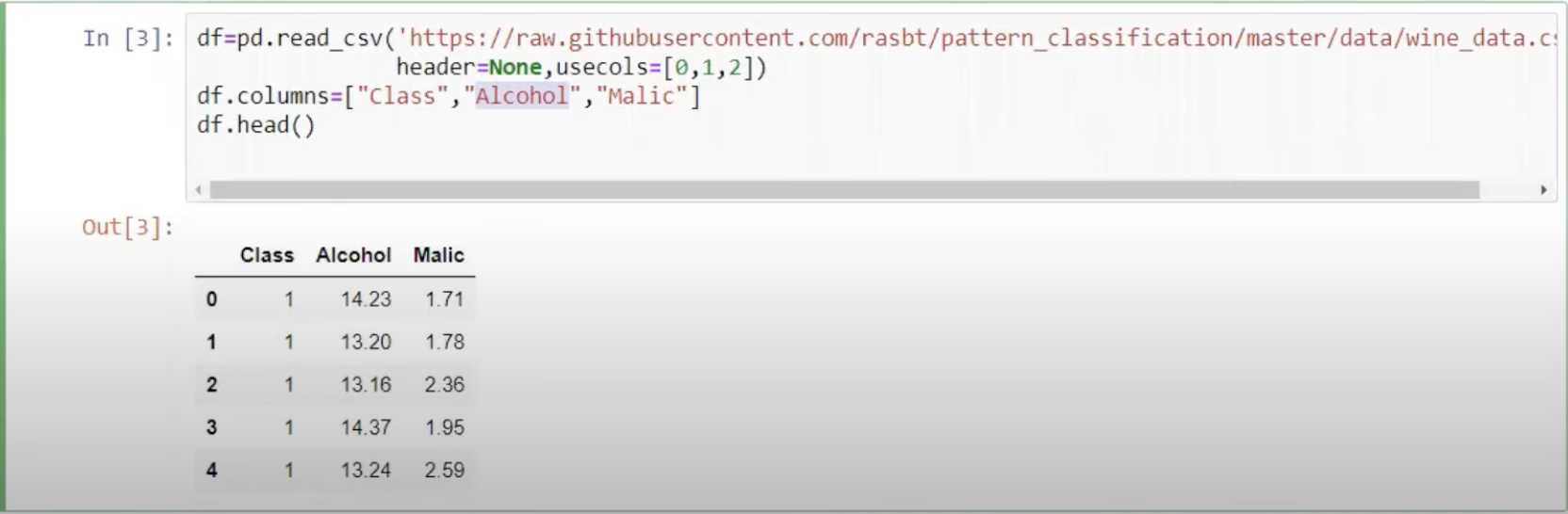[參考圖片來源](https://www.youtube.com/watch?v=mnKm3YP56PY) 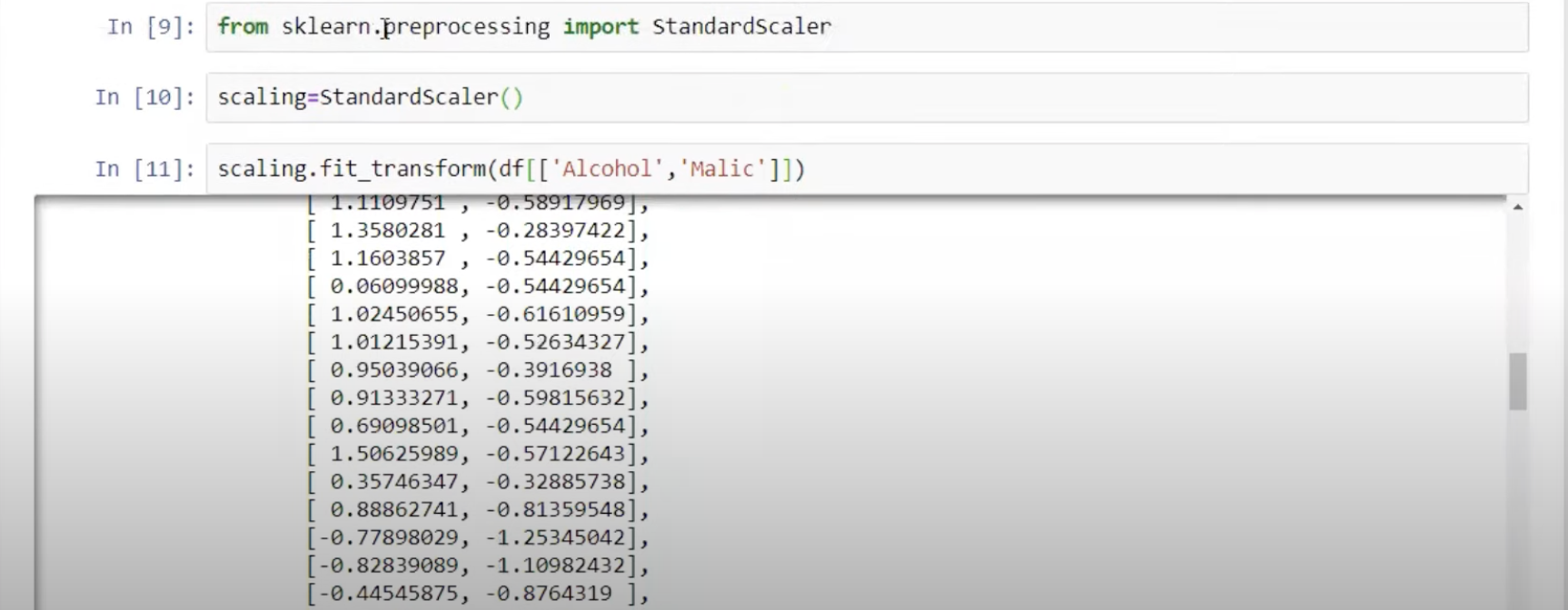[參考圖片來源](https://www.youtube.com/watch?v=mnKm3YP56PY) normalization的好處總結如下: * **提升模型的收斂速度**: 在建構機器學習模型時,我們會利用梯度下降法(Gradient Descent)來計算成本函數(Cost Function)的最佳解;假設我們現有兩個特徵值 x^1 in [0,1] 與 x^2 in [0,10000],則在 x^1-x^2平面上成本函數的等高線會呈獻出一個窄長的橢圓型,導致在梯度下降時需要較多的迭代步驟,另外也可能導致無法收斂的情況發生。因此,若將資料標準化,則能減少梯度下降法的收斂時間。 * **提高模型的精準度**: 將特徵值 x^1 及 x^2 輸入進一些需計算樣本彼此的距離(例如:歐氏距離)分類器演算法中,因為x^1的取值範圍比較小,則 x^2 的影響很可能將遠大於 x^1,若實際上 x^1 的指標意義及重要性高於 x^2,這將導致我們分析的結果失真。在多指標評價體系中,由於各評價指標的性質不同,通常具有不同的量綱和數量級。當各指標間的水平相差很大時,如果直接用原始指標值進行分析,就會突出數值較高的指標在綜合分析中的作用,相對削弱數值水平較低指標的作用。因此,為了保證結果的可靠性,需要對原始指標資料進行標準化處理,資料的標準化可讓每個特徵值對結果做出相近程度的貢獻。 ---------------------- 有興趣進一步了解的人可參考以下連結: * [Standardization Vs Normalization- Feature Scaling](https://www.youtube.com/watch?v=mnKm3YP56PY) * [【資料科學】 - 資料的正規化與標準化](https://aifreeblog.herokuapp.com/posts/54/data_science_203/) * [莫煩-正规化 Normalization](https://mofanpy.com/tutorials/machine-learning/sklearn/normalization/#%E6%95%B0%E6%8D%AE%E6%A0%87%E5%87%86%E5%8C%96%E5%AF%B9%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%88%90%E6%95%88%E7%9A%84%E5%BD%B1%E5%93%8D) * [歸一化的好處及歸一化,標準化的處理方法](https://codertw.com/%E7%A8%8B%E5%BC%8F%E8%AA%9E%E8%A8%80/33768/)