【QA】如何處理不平衡資料(imbalanced data)?
不平衡資料是指資料中某個類別數量會特別多,或特別少, 容易導致模型訓練或預測時數量多的類別容易被預測到, 但有些情境(例如:預測罕見疾病風險),目的其實是希望預測到數量少的類別, 因此需要針對不平衡資料做些處理, 請問常見的不平衡資料有哪些呢?
回答列表
-
2021/08/18 下午 06:06王健安贊同數:0不贊同數:0留言數:1
大家好, 不平衡資料是因為「有」與「沒有」的資料數量差距過大所導致的, 因此最終目標是「減少兩類別資料數量的差距」, 可分為兩大方向:生成類別數量少的資料、抽樣類別數量多的資料。 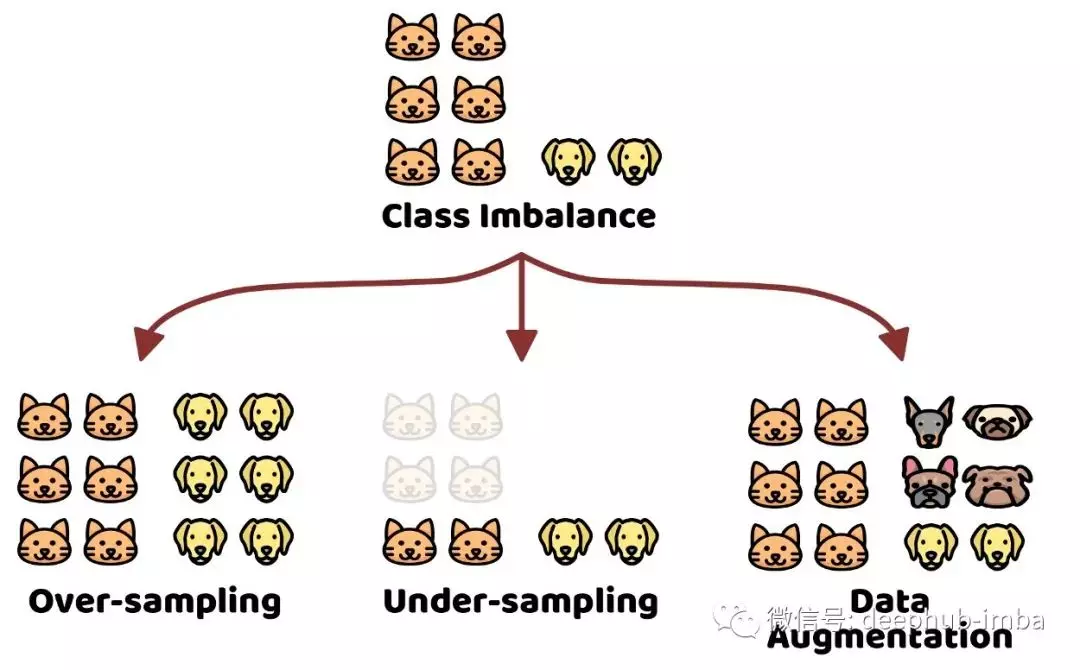 以下總括有一下常見的作法: 1. under sampling:把類別多的資料進行隨機抽樣,藉由減少多量資料達到兩類別資料數量一致的目的。 2. over sampling:把類別少的資料進行重複性地隨機抽樣,藉由增加少量資料達到兩類別資料數量一致的目的。 3. SMOTE:以少類別資料為基礎,生成特定範圍的資料,藉由增加少量資料達到兩類別資料數量一致的目的。 4. GAN:透過深度學習方法進行生成資料,藉由增加少量資料達到兩類別資料數量一致的目的。 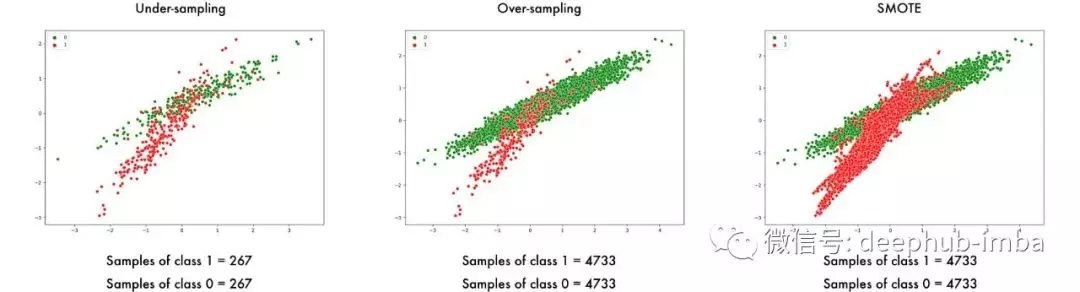 參考答案: MdEditor:通過隨機取樣和資料增強來解決資料不平衡的問題 https://www.gushiciku.cn/pl/gsy3/zh-tw 知識星球:學習| 如何處理不平衡資料集 https://www.ipshop.xyz/14760.html