【QA】如何透過L1, L2 正規化處理過擬合(Overfitting)問題?
2021/08/11 下午 08:56
機器學習共學討論版
Chili
觀看數:162
回答數:1
收藏數:1
在現今的機器模型當中,可以發現很多正規化的處理方式,來解決過擬合(Overfitting)問題,其中L1, L2 為最基本的正規化處理方式,我想跟大家討論一下,兩者是如何解決過擬合(Overfitting)問題。
回答列表
-
2021/08/11 下午 09:01Chili贊同數:0不贊同數:0留言數:0
* Loss function: 定義為y (真實值) 與 y hat (模型預測值)的差額,當loss 越小表示模型越準確,我們也藉此來判斷這模型的好壞。 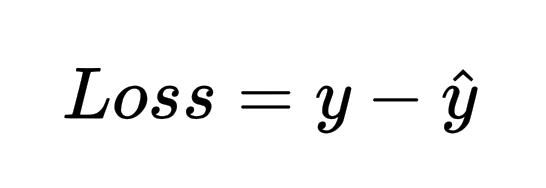 ------- * 懲罰項: 為了要解決模型越訓練越複雜的情況,我們在loss function 中加入懲罰項,讓模型在訓練時不會過度複雜化,當訓練越來越複雜時,loss值也會相對應增加。 ------- _接下來舉一個例子來說明_ 假設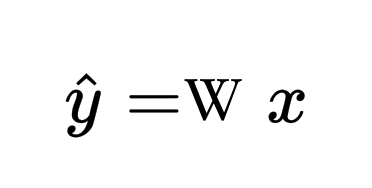 * 其中W表示為模型的各種參數 * 加入懲罰項後的Loss function: (fs>18: **L1 正規化:**