【QA】L1正規化(Regularization)與L2正規化的差異之處?
在機器學習模型當中有很多的正規化方法,其中L1, L2 正規化為最基本的方式,由於兩個方法在數學式上面,蠻相近的,但卻有不同的應用與優缺點。 # 比較圖表:  * Robust表示:有很好的抗干擾能力,異常點可以安全的和高效的忽略,這對研究幫助很大。 (但如果研究的異常值很重要,L2則是更好的選擇。) * 穩定性:不會輕易受資料集移動影響。 --------------------------------------------------------------------------------------------------- 假設一情況,我們現在在預測一個籃球員的表現,我們用的特徵有身高、體重、投籃準度、喜歡吃的食物。 方程式可以寫成: **_表現 = b0 + b1身高 +b2 體重 + b3準度 + b4 食物_** 但其中**喜歡吃的食物**這特徵並不重要,我們應該要處理他,使得模型可以更好的預測,並解決_**模型overfitting 的問題**_,因此我們會從其參數b4下手,讓其變小或是變為0。 L1, L2 正規化最大的差異就是, **L1**習慣於將模型中不重要的特徵參數變為0,換句話說是**減少模型中的特徵**。 而**L2**是將不重要特徵參數接近0,但不為0,保留這特徵,但**降低對整體的影響力**。 下面我想跟大家討論造成兩個不同之處的原因。
回答列表
-
2021/08/11 下午 07:55Chili贊同數:0不贊同數:0留言數:0
# 造成差異的原因: 接下來,我們先通過視覺化的方式,一步一步讓大家能以更直覺的方式來理解造成L1, L2 的差異的原因。 假設我們需要訓練的模型長這樣: 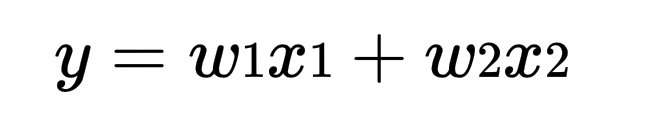 首先我們要透過L1, L2正規化處理overfitting 的問題,因此我們的目標是在_(fs>24:**限制W1, W2 的情況下,找到最小的MSE**_