【QA】什麼是強化學習裡頭的Policy Gradient演算法?
在強化學習裡頭,在選擇Actor動作上,有兩大典型的演算法,分別是基於概率(Policy-based)的Policy Gradient,以及基於價值(Value-based)的Q-learning,他們各自都有自己的優缺點,以及適合應用的場合。而這次我想跟大家討論的為基於概率的Policy Gradient,背後運作原理。
回答列表
-
2021/09/15 下午 08:30Chili贊同數:0不贊同數:0留言數:0
# 什麼是Policy Gradient? 就是一個神經網絡,輸入是狀態,輸出直接就是動作。 當Network準備輸出某動作Action,其Reward為最高時,Policy Gradient做該Action的機率就會增大。 我們利用Network來預測Action時,Policy Gradient可以透過Reward來進行反向傳播,更新參數。 --- # 我們先來解釋一些名詞: * Policy : 就是強化學習中的network,功用在於決定actor * Θ: 為這個Network中的參數 * Trajectory:τ={s1,a1,s2,a2,...,sT,aT},為整個episode串連起來的事件們。 * pθ(τ):在參數Θ給定的情況下,某Trajectory發生的機率 * R(τ):∑Tt=1rt,reward function是將一整個trajectory的reward加起來 * Rθ:∑τR(τ)pθ(τ)=Eτ∼pθ(τ)[R(τ)],為R的期望值。計算方式為,給定Θ的情況下,窮舉出所有可能的trajectory,計算全部的Reward,並加權乘上出現τ的機率。 *因為Reward本身是隨機的變數,無法計算 而Rθ就是我們要做Gradient 的部分 我們利用Gradient Ascent 的方式來最大化Reward Function (因為是要讓Reward越來越大,所以是Ascent) --- # 整個流程為: 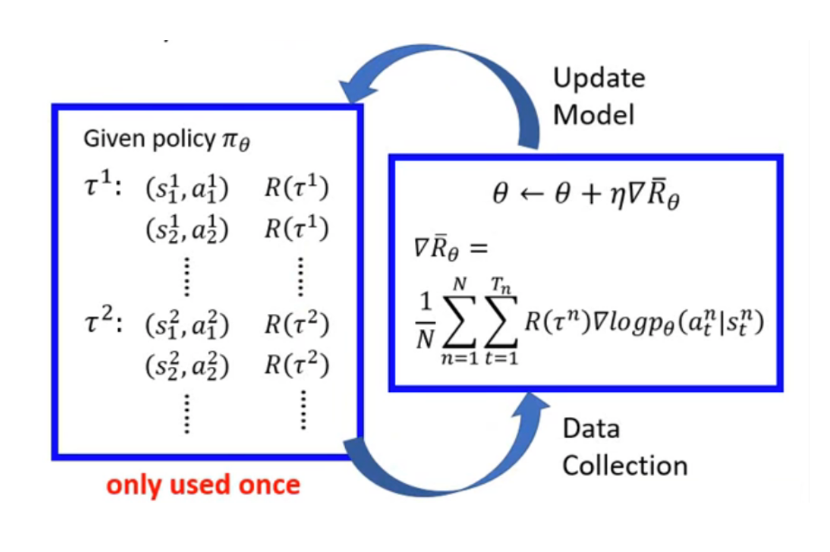 [圖片來源](https://www.youtube.com/watch?v=z95ZYgPgXOY) * 先收集State與 Action的資料 * 與環境互動,取得Reward * 將資料帶到公式中,計算梯度 * 更新梯度 * 重新收集資料 (一般Policy Gradient 收集到的資料只能用一次,下次更新需要重新收集資料) --- * 參考資料: 莫凡簡單的講解: https://www.youtube.com/watch?v=cw0USSxeEzw 李宏毅老師的詳細講解: https://www.youtube.com/watch?v=z95ZYgPgXOY https://hackmd.io/@shaoeChen/Bywb8YLKS/https%3A%2F%2Fhackmd.io%2F%40shaoeChen%2FHkH2hSKuS